관찰된 분포가 이론상의 분포에 얼마나 잘 맞는가?
범주형 자료에 대한 추론
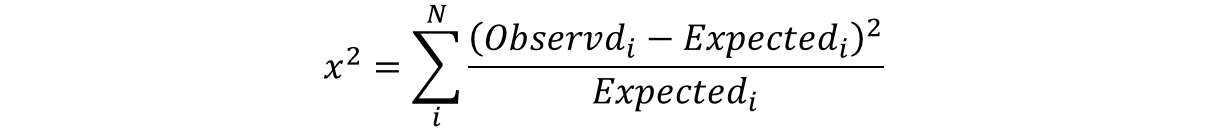
one-sample 카이제곱값을 구하는 코드 만들어보기!
import numpy as np
import pandas as pd
### 1. 넘파이 이용
## 넘파이를 통한 구현
ar1=np.array(df1)
ar2=ar1.mean()
arr_chi=(ar1-ar2)**2/ar2
chi=arr_chi.sum()
chi
### 2. DataFrame 사용
df4=pd.DataFrame(df1)
mean=df4.DT.sum()/4 #979.25
df4['expected']=mean
df4['up'] = df4.apply(lambda x:
(x['DT']-x['expected'])**2 ,axis=1)
df4['chi']=df4.apply(lambda x:
x['up']/x['expected'], axis=1)
df4.chi.sum()
### 3. stats module 사용
stats.chisquare(df1)[0]

지역에 대한 1샘플 카이제곱검정
지역별 미분양 주택수의 합이 같은가 다른가?
import pandas as pd
import numpy as np
import seaborn as sns
import requests
#8월지정
url1='https://kosis.kr/openapi/Param/statisticsParameterData.do?method=getList&apiKey=NzE2OGY3ODQxZjNkMWMyOWUyYTYxMjVhN2UxOGRlNzI=&itmId=13103792722T1+&objL1=ALL&objL2=ALL&objL3=ALL&objL4=&objL5=&objL6=&objL7=&objL8=&format=json&jsonVD=Y&prdSe=M&startPrdDe=202008&endPrdDe=202008&loadGubun=2&orgId=116&tblId=DT_MLTM_2080'
response=requests.get(url1)
json=response.json()
dfraw=pd.json_normalize(json)
dfraw.fillna(0)
dfraw2 = dfraw[dfraw.columns[-6:]]
dfraw2
기본 전처리
df=dfraw2.query("(C1_NM=='서울' or C1_NM=='대전'or C1_NM=='대구'or C1_NM=='부산' )")
df.drop(columns=['PRD_SE','C1'], inplace=True)
select=df.C3_NM.unique()[2:] #array(['60㎡이하', '60〜85㎡', '85㎡초과'], dtype=object)
df['TF']=df.C3_NM.apply(lambda x: None if x=='총합' or x=='소계' else x)
df.dropna(axis=0, inplace=True)
df4.reset_index(drop=True, inplace=True)
df['DT']=df.DT.astype('int')
df1=df.groupby("C1_NM").sum()['DT']
df, df1

from scipy import stats
result = stats.chisquare(df1)
result
# Power_divergenceResult(statistic=1564.4572376818994, pvalue=0.0)결과
$𝐻_0$ : 지역별 미분양 주택수의 합은 같다. (고르게 분포)
$𝐻_1$ : 지역별 미분양 주택수의 합이 같지 않다. (고르지 않게 분포)
𝛼 : 0.05
𝑃−𝑣𝑎𝑙𝑢𝑒 : 0.0
따라서 귀무가설 기각. 대립가설 채택.
지역별 미분양 주택수의 합이 고르지 않게 분포하였다
(지역별 차이가 존재한다)
지역과 규모에 대하여 two sample chi square test
기본 전처리
tmp=df.query('C2_NM=="민간부문"').set_index(['C1_NM','TF'])['DT'].unstack()
cols=tmp.columns
tmp=tmp[[cols[1],cols[0],cols[2]]]
tmp
카이제곱 검정 시행
chi, p, dof, expected = stats.chi2_contingency(tmp)
print(f"chi 스퀘어 값: {chi}",
f"p-value (a = 0.05): {p}",
f"자유도 수: {dof}",
f"기대값: \n{pd.DataFrame(expected)}",
f"측정값: \n{tmp}", sep = "\n" )
결과
$𝐻_0$ : 지역별 그룹(평수) 간 차이가 없다
$𝐻_1$ : 지역별 그룹(평수) 간 차이가 있다.
𝛼 : 0.05
𝑃−𝑣𝑎𝑙𝑢𝑒 : 0.0
따라서 귀무가설 기각. 대립가설 채택.
지역별 평수가 고르지 않게 분포하였다
(지역별 평수간 차이가 존재한다)
참고 : https://m.blog.naver.com/PostView.nhn?blogId=parksehoon1971&logNo=221589203965&proxyReferer=https:%2F%2Fwww.google.com%2F
https://stackoverflow.com/questions/11725115/p-value-from-chi-sq-test-statistic-in-python
'Statistics' 카테고리의 다른 글
| 중심극한정리(CLT), 큰 수의 법칙(Law of large numbers) (0) | 2021.01.27 |
|---|---|
| Covariance and Correlation 상관계수 (0) | 2021.01.27 |
| P-value란? (0) | 2021.01.27 |
| T-Test, Chi-Square (0) | 2021.01.27 |
| Type of Error (0) | 2021.01.27 |