여러 활성화 함수가 있지만, 가장 많이 쓰이는 몇개의 활성화 함수만 간단히 정리해보자
Sigmoid 시그모이드
$${\sigma(X)} = {1\over{1+e^{-x}}}$$
$$\sigma^\prime(X)= \sigma(x)(1-\sigma(x))$$


시그모이드 함수는 개별 뉴런이 내뱉어 주는 값을 S자 커브형태로 활성화시켜주며, 0~1 사이의 값을 뱉어준다.
다만, 입력값의 절대값이 5를 넘어갈 경우 그래디언트값이 상당히 작아짐 → 학습이 잘 안됨
자연상수 e 의 연산이 다소 무겁다는 단점이 있다.
하이퍼볼릭 탄젠트
시그모이드 함수의 크기와 위치를 조절한 함수이다.
$${tanh(x)} = {2\sigma(2x) - 1} = {{e^x-e^{-x}}\over{e^x + e^{-x}}}$$
$$tanh^\prime(x) = 1\ -\ tanh^2(x)$$
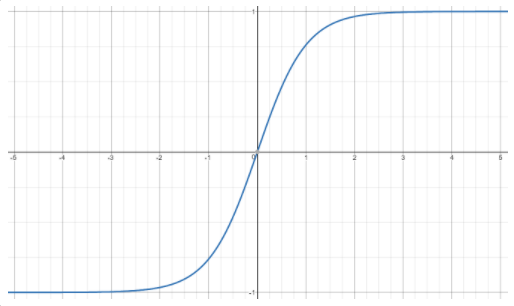

하이퍼볼릭 탄젠트의 범위는 [-1,1]이다. 그리고 시그모이드와 달리 0을 기준으로 대칭이다.
위 두가지 특징이 시그모이드를 활성화함수로 쓸 때 보다 학습 수렴 속도가 빨라지게 한다.
tanh 또한, x가 5 이상 넘어가는 순간부터 기울기가 상당히 작아지는것을 볼 수 있다.
Rectified linear Unit (ReLU)
$f(x)\ = \ max(0,\ x)$

0보다 커지는 순간 값만큼 그대로 간다.
x가 양수이기만 하다면 기울기가 1로 일정하므로, 기울기 소실의 문제를 피할 수 있고, 미분이 편리해 계산이 매우 빠르다.
하지만 단점으로 x가 음수라면 기울기가 무조건 0이 된다는 단점이 있으며, 이를 보완하여 Leaky ReLU가 나왔다.
Leaky ReLU
$f(x) = max(0.01x, x)$

x가 음수일때 그래디언트가 0.01 이라는 점을 제외하고는 ReLU와 같은 특성을 지닌다.
참조
[Deep Learning-딥러닝]Activation Function-활성화 함수(Sigmoid, Hyperbolic Tangent, Softmax, ReLu)
https://ratsgo.github.io/deep learning/2017/04/22/NNtricks/