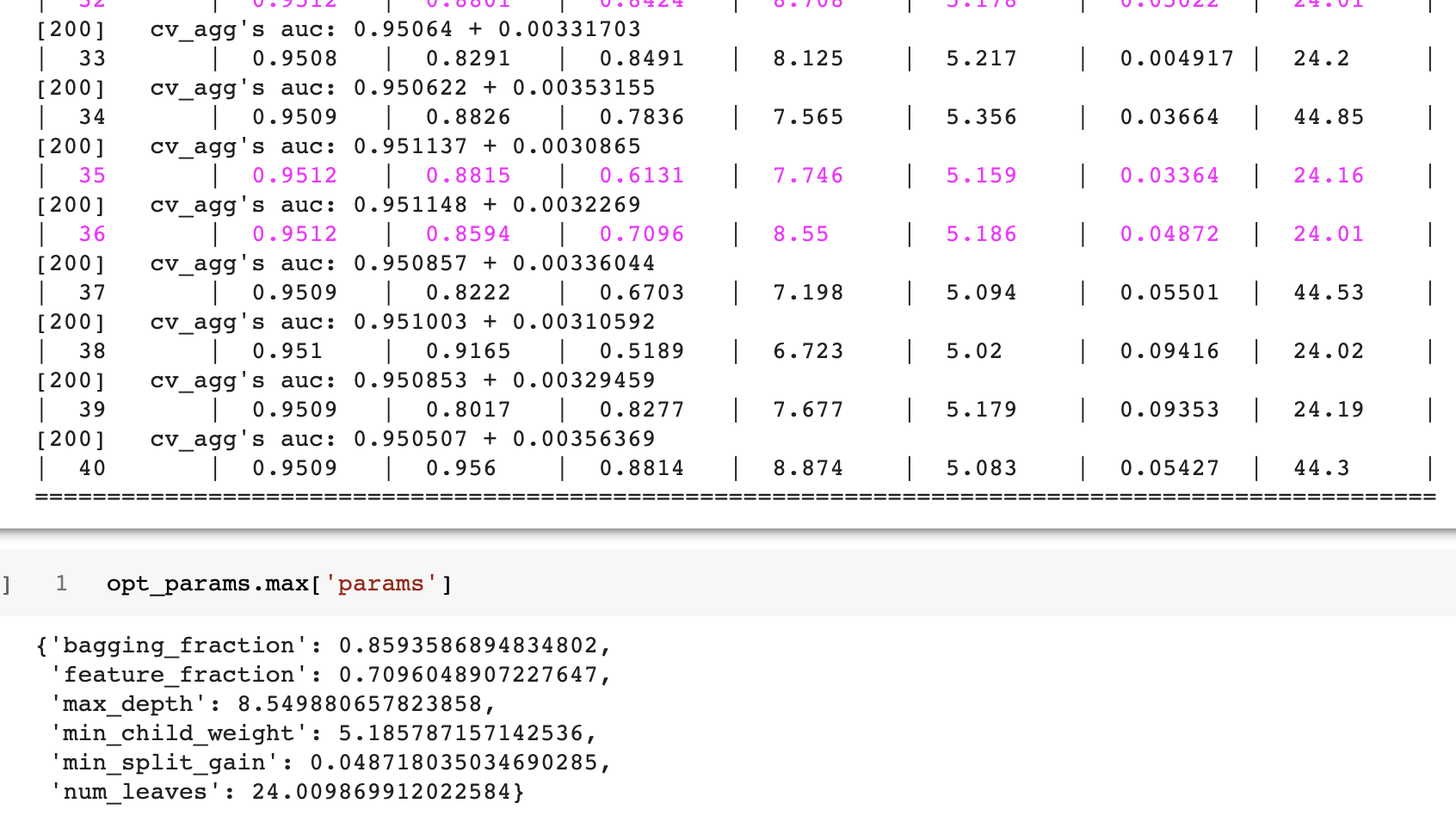
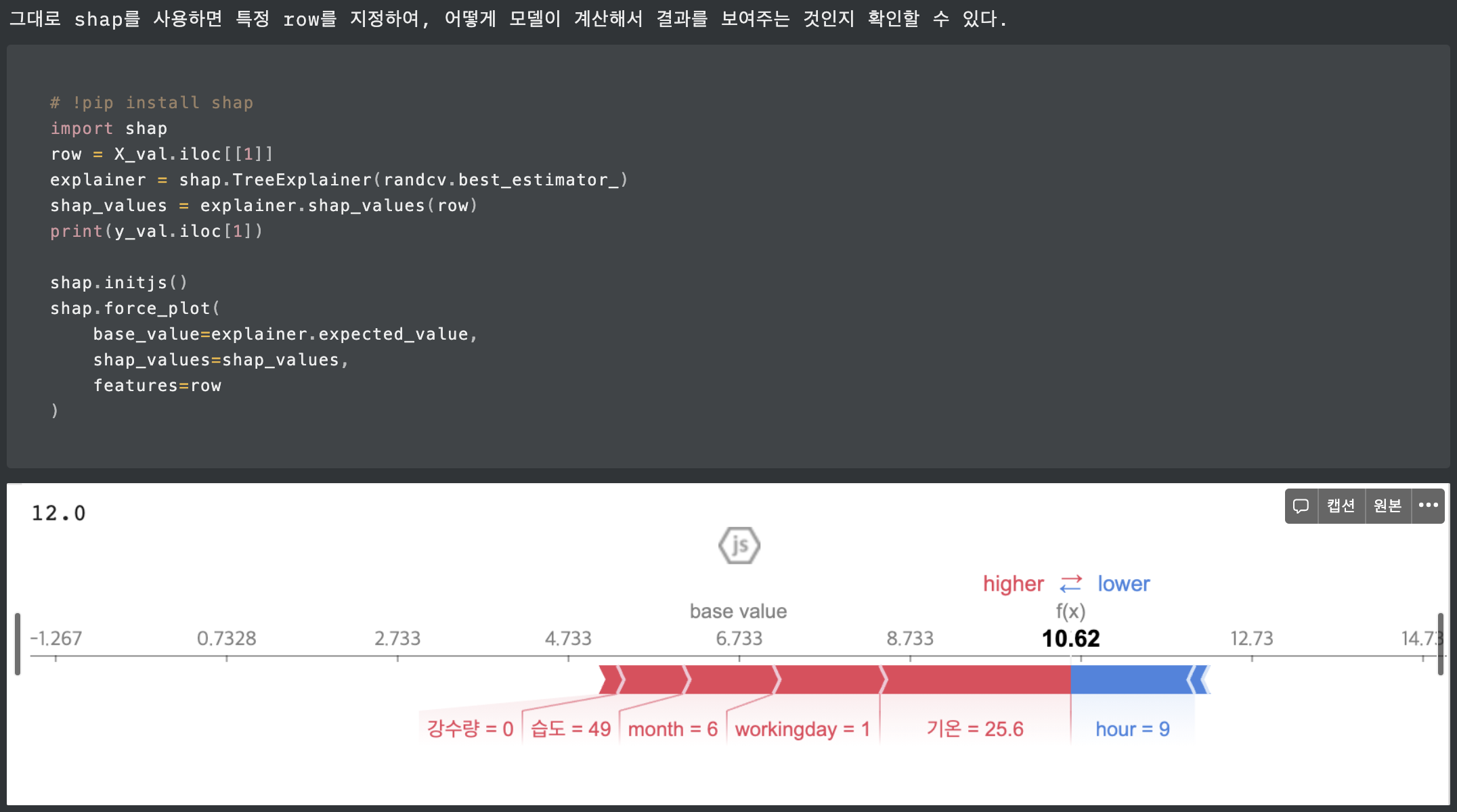
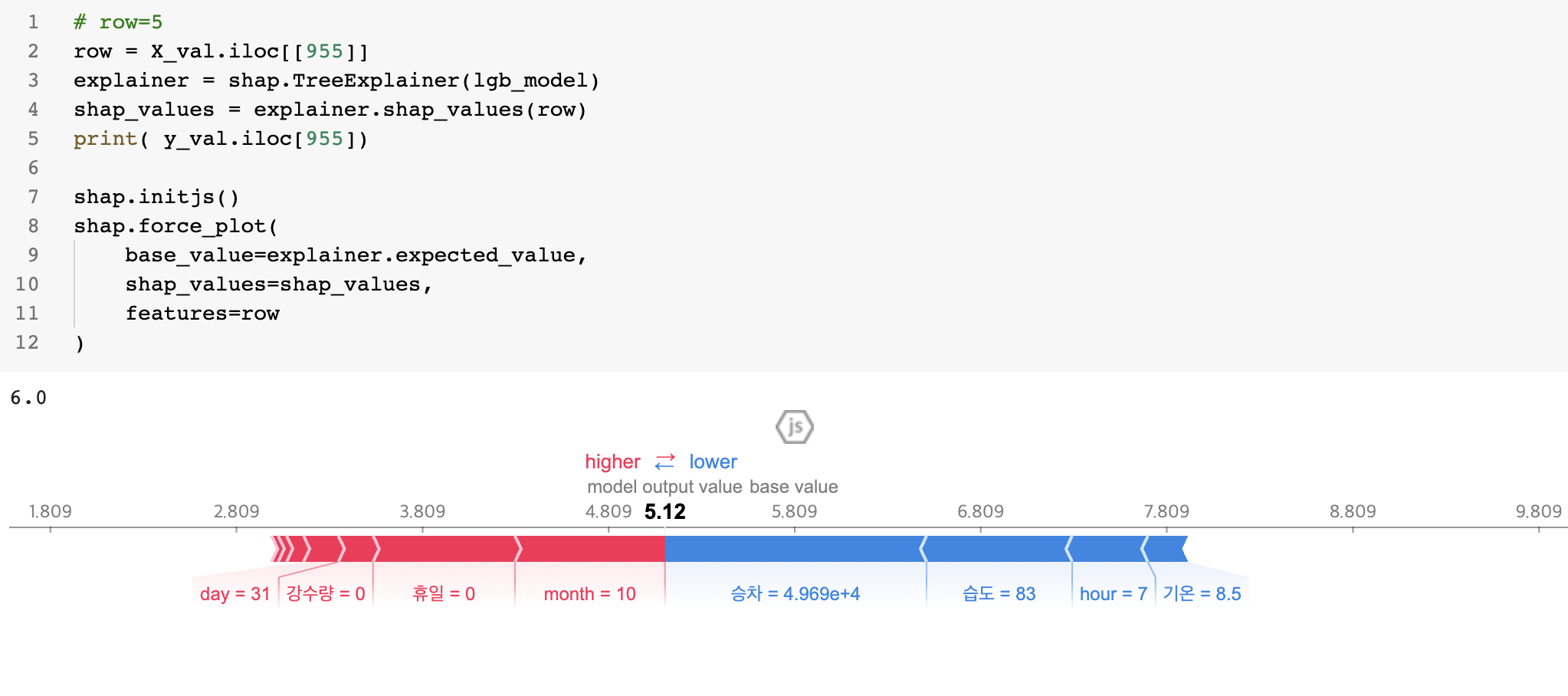
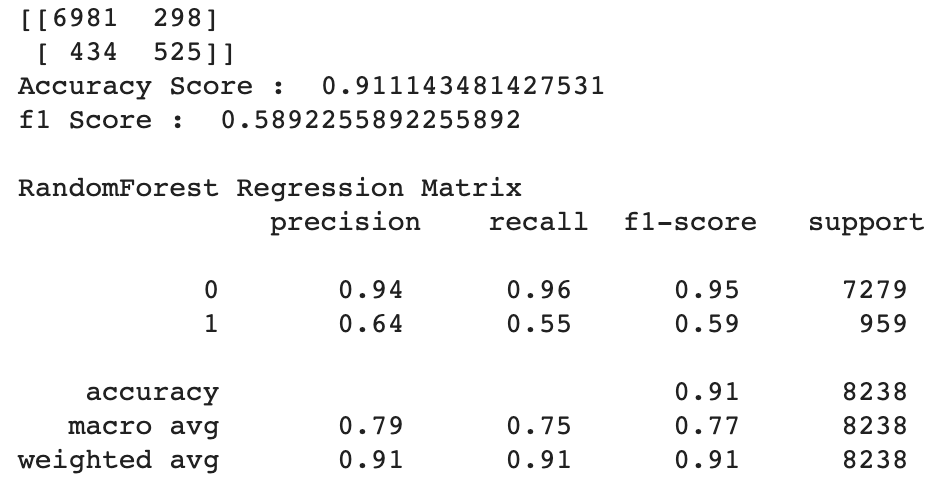
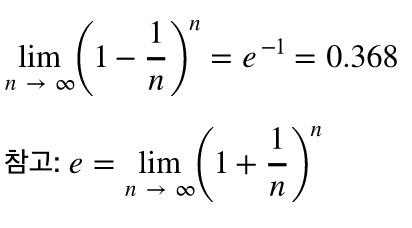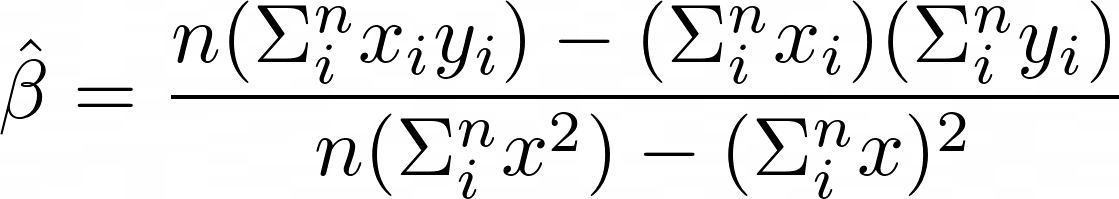틀릴 수 있는 정보를 갖고 구한 엔트로피. 즉 불확실성 정도의 양이라고 할 수 있는데, 이 틀릴 수 있는 정보는 바로 머신러닝모델의 아웃풋이 있다. 모델의 아웃풋은 예측값이기에 틀릴 수 있다.
Cross Entropy is optimal entropy When ifro is from estimated probability
간단한 딥러닝 분류문제이다. 최종단에 softmax레이어가있고, 이것을 활용해 예측값을 구할 수 있다. 이것을 정답과 비교할 땐 정답값을 원-핫 인코딩으로 비교하는 형태이다. 이 과정에서 softmax값과 one-hot인코딩된 실제 값을 사용한다.
소프트맥스 값을 Q라고 하고, 실제 라벨을 P라고 했을 때 Q : Estimated Probability , P : True Probability
H(P,Q)가 크로스 엔트로피 공식이고, H(X)가 엔트로피 공식이다. 각각 클래스마다 어떤 확률로 존재하는지를 나타낸다 -> 여기서 $p_i$는 (어떠한 정보의) 확률이다.
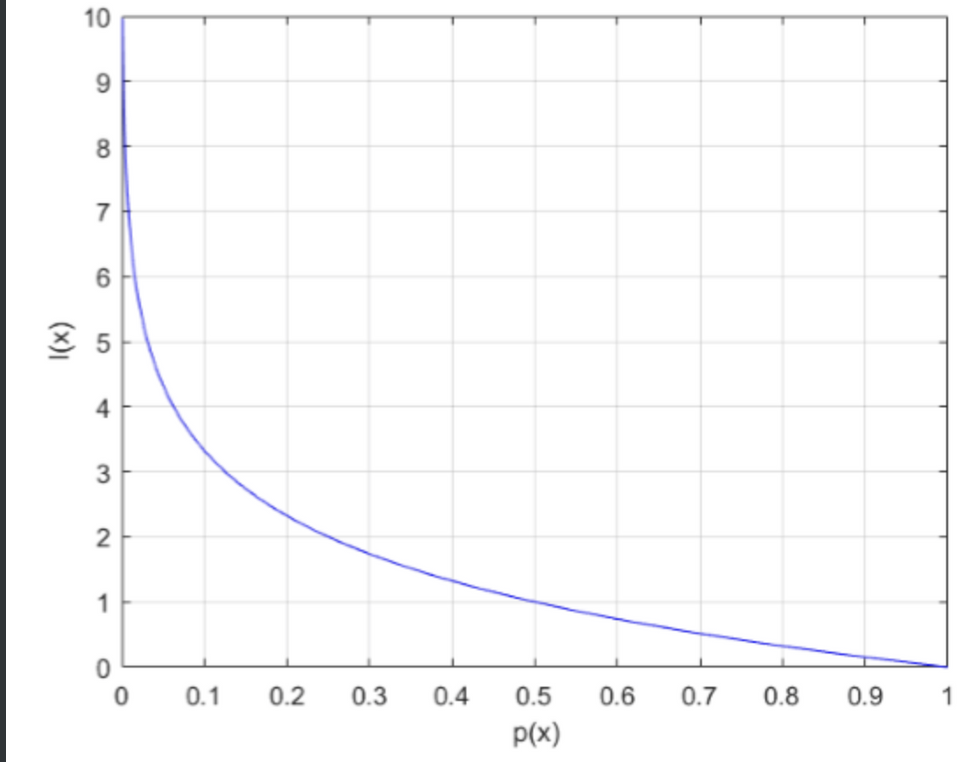
$ log_2{1\over{q_i}}$ 는 정보의 양을 나타낸다
왜 크로스엔트로피에서 정보의 양에 $log_2$ $1\over{q_i}$ 을 사용하는걸까?
첫번쨰로 우리는 딥러닝 모델을 학습시킬때 이 예측값이 정답과 얼마나 근사한지 알고싶다. 그를 위해 실제 확률값을 사용해야한다. 단 정보의 양은 모델을 통해 온 정보의 양(예측값의 확률)을 사용해야해서 위의 log 안에 q 가 들어간것이다. 실제 정답의 확률을 사용함으로써 이 엔트로피값이 과연 실제 정답값과 얼마나 근사한지를 알 수 있게되는것이다.
틀릴 수 있는 정보를 갖고 구한 엔트로피값이다 라고 한마디로 정리할 수 있다.
KL Divergence
단순히 어떠한 모델을 설명할때, 차이가 크다-작다 보다 정확한 수치로 얼마만큼 차이난다! 라고 나타냄으로써 어떤 모델이 더 정답과 비슷하게 유추하는지 나타낼 수 있도록 하기위하여 KL Divergence를 사용한다. 이는 수치값으로 분포도를 나타낸다.
P : 정답, Qa : 모델a, Qb : 모델b
$Q_A$가 실제 정답과 상당히 비슷한 분포를 갖고있다고 할 수 있다.
KL Divergence는 실제 정답값의 분포도에서 상대적으로 얼마만큼 다른지에 대해 수치적으로 나타내는 값이다.
상대엔트로피값과 같다.
1. 항상 0과 같거나, 0보다 크다. 2. 비대칭적이다.
그렇다면 왜? 크로스엔트로피를 cost func으로 쓰고, minimize함으로써 최적화를 하는데, 왜 KL Divergence를 쓰지 않는가?
실제로, 크로스엔트로피를 쓰거나, KL Divergence를 쓰거나 같은 현상을 일으킨다.
결국 KL-Divergence 를 사용해도, Entropy(P)가 상수이므로 뒷부분이 무시되고, 크로스엔트로피를 쓰는것과 같은 효과를 발휘하는것.
Learning Rate를 eta라고 하는데, 각 Output Value에 이를 곱하여 사용한다.
Prediction
시리즈 1번에서의 예시자료를 그대로 사용하면,
이로써, 초기의 예측 0.5에서 -2.65로 한층 더 가까워졌다.
나머지 값들도 예측을 진행
2,3,4번의 값들도 각각의 Leaf에 맞는 output Value를 사용하여 새로운 예측을 하였고, 이로써 Initial Prediction보다 좀 더 나아졌다.
이제 이렇게 만들어진 Prediction을 통하여 또 잔차를 계산, 그 잔차들을 통해 Root에 넣고, SS계산 Max_Depth가 허용하는 만큼 or leaf에 하나남을때 까지 Split 지점을 찾아서 (최대 Gain을 기준으로) Split 진행, 최종 Split 후 Gamma 값에 따라서 Gain과 비교하여 Pruning진행, Pruning 까지 진행한 후 Output Value를 계산, Initial Prediction부터 이전 트리까지의 Output Value와 Learning Rate를 사용하여 새로운 Prediction 을 한다.
위 과정을 Maximum Number에 닿을때 까지 or 더이상 진전이 없을때 까지 반복하면 점차점차 각각의 값들에 맞는 Tree들이 만들어지고, 그렇게 모델이 학습된다!
Gain이 최대가 되는 Split지점을 찾아서 트리만들고 SS계산
Gain과 Gamma값의 비교를 통하여 Pruning
Leaf의 Output Value를 계산
아래는 StatQuest의 XGBoost Mathmatical Detail을 들으며,,,, 열심히 정리하며 이해하려 노력한 흔적이다!
테일러 근사를 통해 Loss Function을 쉽게 근사하고, Gradient와 Gession을 통해 식을 편하게 바꾸고나서 풀고 정리하고 풀고 정리하면, 어떻게 Output Value 식이 만들어졌는지 알 수 있다.!
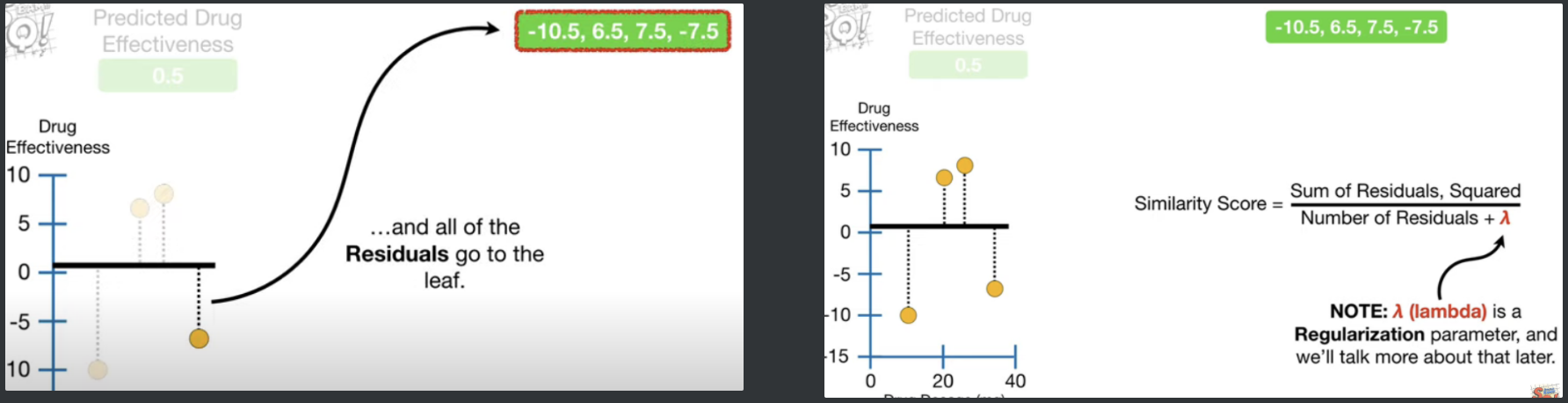
SS(Similarity Score) 계산이 끝나면 이제 이 리프를 분기시켜서 트리를 만들어본다. 4개의 데이터 사이에 분기점을 만들면 총 3개를 만들 수 있고, 이렇게 분기되는 때마다 SS를 계산하여, Gain을 계산한다. 각 트리를 만들때마다 왼쪽, 오른쪽 리프의 SS계산을 하여 기록하면 이제 분기 전후에 대한 비교가 가능해진다. 분기 전에는 7.5와 -7.5가 서로 상쇄시켜서 ss가 낮았던 반면, 분기 후엔, 왼쪽 오른쪽 리프들 각각 상쇄작용이 약해서 ss점수가 더 크다.
이제 각 분기점에 대한 Gain을 계산하는데, Gain의 식은 이러하다. $$Gain = Left_{Similarity} + Right_{Similarity} - ROOT_{Similarity}$$
분기점을 2,3번 데이터 사이(Dosage<22.5)로 했을 때 Gain = 8 + 0 - 4 = 4
이제 분기점을 3,4번 데이터 사이 (Dosage < 30)으로 했을 때를 계산하면
분기점을 3,4번 데이터 사이(Dosage < 30)으로 했을 때 Gain = 56.33
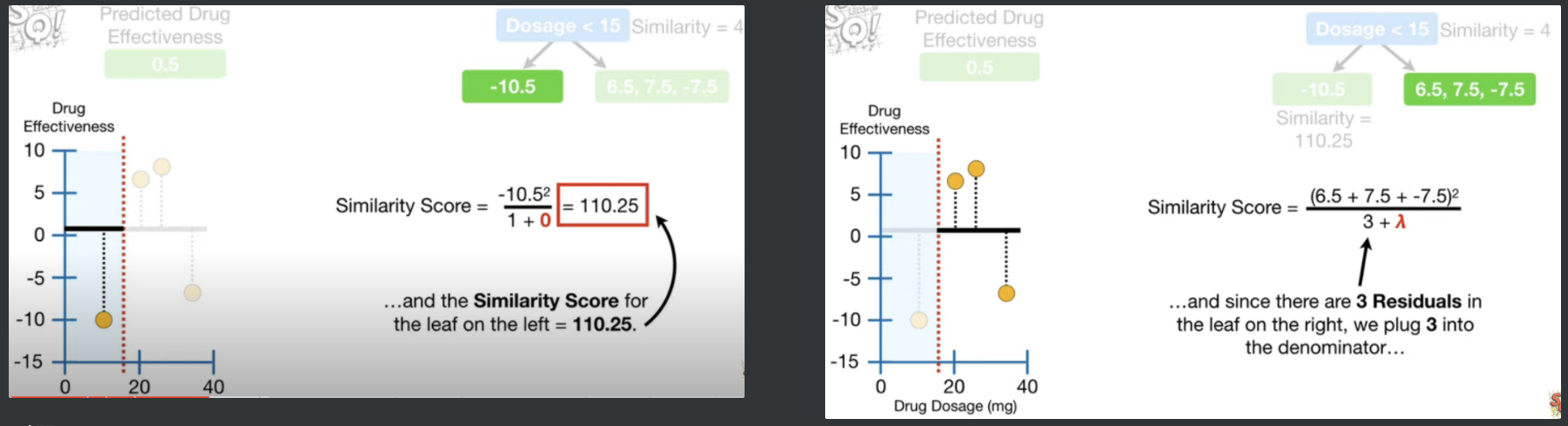
더이상 관측치 사이에 Split 할 것이 없다. 따라서 각 분기점의 Gain을 비교하면, 1,2번 사이의 Gain (120.33)이 가장 크므로, Dosage < 15을 선택. 왼쪽 리프에는 -10.5 하나만 들어와있고, 오른쪽엔 6.5, 7.5, -7.5가 들어와있다.
이제 오른쪽 리프에 3개를 분할해보는데, 맨 처음 루트에서 SS와 각각 split지점에 대한 SS, Gain을 계산했던 것과 동일하게 진행한다. 2,3번 사이에 split을 하면, 아래 그림과 같이 나눠지고
3,4번 사이에 split을 하면, 아래 그림과 같은 분기가 이루어지고, 이 떄의 SS를 계산하면 각각 $SS_{(Dosage<30)} = { {(6.5+7.5-7.5)^2}\over{3+0} } = 14.08 $ , $SS_{left}= {{(6.5+7.5)^2}\over{2+0} }= 98$ , $SS_{right}= { { (-7.5)^2 } \over {2+0} } = 56.25$이고, ${Gain} = { SS_{left} + SS_{right} - SS_{ROOT} } = {98 + 56.25 - 14.08} = 140.17$ 이다.
22.5로 나눴을 때 보다, 30으로 나눴을 때 더욱 Gain이 크므로, Dosage < 30 을 선택한다. 이후, max_depth (default = 6) 이 허용하는 만큼 한번 더 왼쪽 리프를 분기할 수 있지만, 계산을 간편히 하기위해 max_depth = 2로 제한하여 분기종료.
이로써, SS Score와 Gain 을 통하여 트리를 만들었다. 이제 트리를 Prune해야한다. Prune에서는 Gamma($\gamma$)를 사용한다. Gain보다 $\gamma$가 크면 가지친것을 삭제하는 것이다.
$\gamma = 130$이라면, 오른쪽 분기점의 Gain ( 140.17 )이 더 크므로 오른쪽 brunch가 살아남는다, 이에따라, 루트도 함께 살아남게된다.
만약 $\gamma=150$이라면?
먼저 오른쪽 brunch의 gain이 150보다 작으므로, 삭제하고, 루트또한 gain이 120.33으로 150보다 작으므로 이번에 만든 트리 자체를 날려버리는 것이다.
$\lambda$의 역할은?
람다가 어떤 정규화 파라미터로 작용한다는 것은 앞서 설명했다. 하지만 어떻게 작용하길래 정규화 파라미터역할을 하는 것일까? 이는 Similarity Score를 확인하면 알 수 있다.
에서, $\lambda$가 커질수록, SS는 작아지고, 이에따라 Gain도 같이 작아지게된다. XGBoost에서 Gain에 따라 Pruning을 진행하는데, $\gamma$값보다 Gain이 작으면, 그 트리(or Brunch)를 삭제하므로, 트리가 자주 지워지게되고, 이는 결국 Overfitting을 방지하는 역할을 하게된다!
λ 값에 따른동일 트리에 대한 Gain 차이
λ 값에 따른 Gain의 차이가 위와같다. SS를 계산할 때, λ가 분모에 들어있으므로, λ가 커지면 -> SS가 작아지고, 이에따라 Gain도 작아지는 것이다.
하나의 리프 내 샘플의 수에 따라서 λ가 어떤 영향을 주는가?
SS와 Gain 모두 Number of Residual로, 한 리프에 몇개의 샘플(잔차)이 들어있는지에 영향을 받는다. λ는 모두 분모에 있으며, 이에 대한 영향은 λ가 1만큼 커짐에 따라, Residual이 1개있는 리프는 SS가 $1\over2$만큼 작아진다. 2개있을경우 분모가 2->3으로 변화하므로 한 leaf에 잔차 수가 많으면 많을 수록 λ의 영향이 작다는것이고, 이는 한 leaf의 샘플 수가 많을 수록 λ의 영향이 적어지므로, 향후 파라미터 튜닝에서 λ의 값과, min_samples_leaf를 함께 생각해야 할 것이며 이 둘의 상호 영향또한 염려해야한다는 것으로 이해된다.
Motivation Random Forest 가 병렬적으로 무지 많은 Decision Tree를 만든다면, 부스팅에서는 Decision Tree를 점진적으로 발전시킨 후 이를 통합하는 과정을 한다. AdaBoost와 같이, 중요한 데이터에 대해 weight를 주는방식 vs GBDT와 같이 딮러닝의 loss function 마냥 정답지와 오답지간의 차이를 다음번 훈련에 다시 투입시켜서 gradient를 적극적으로 활용, 모델을 개선하는 방식이 있는데, XGBoost, LightGBM이 이에(후자) 속한다.
LightGBM에서 (GOSS와 EFB방식을 통해) 번들을 구성, 데이터 feature를 줄여서 학습한다
Conventional GBM need to, for every feature, scam all data instances to estimate the information gain of all the possible split points.
GOSS (Gradient-based One-Side Sampling)
Data instances with different gradients play different roles in the computation of information gain
Keep instances with large gradients and randomly drop instances with small gradients
각 데이터들은 서로다른 gradient를 가지며, 이에대한 information gain이 다르다 -> 어느지점을 습득하는지에 따라 다른 역할을 수행하게된다.
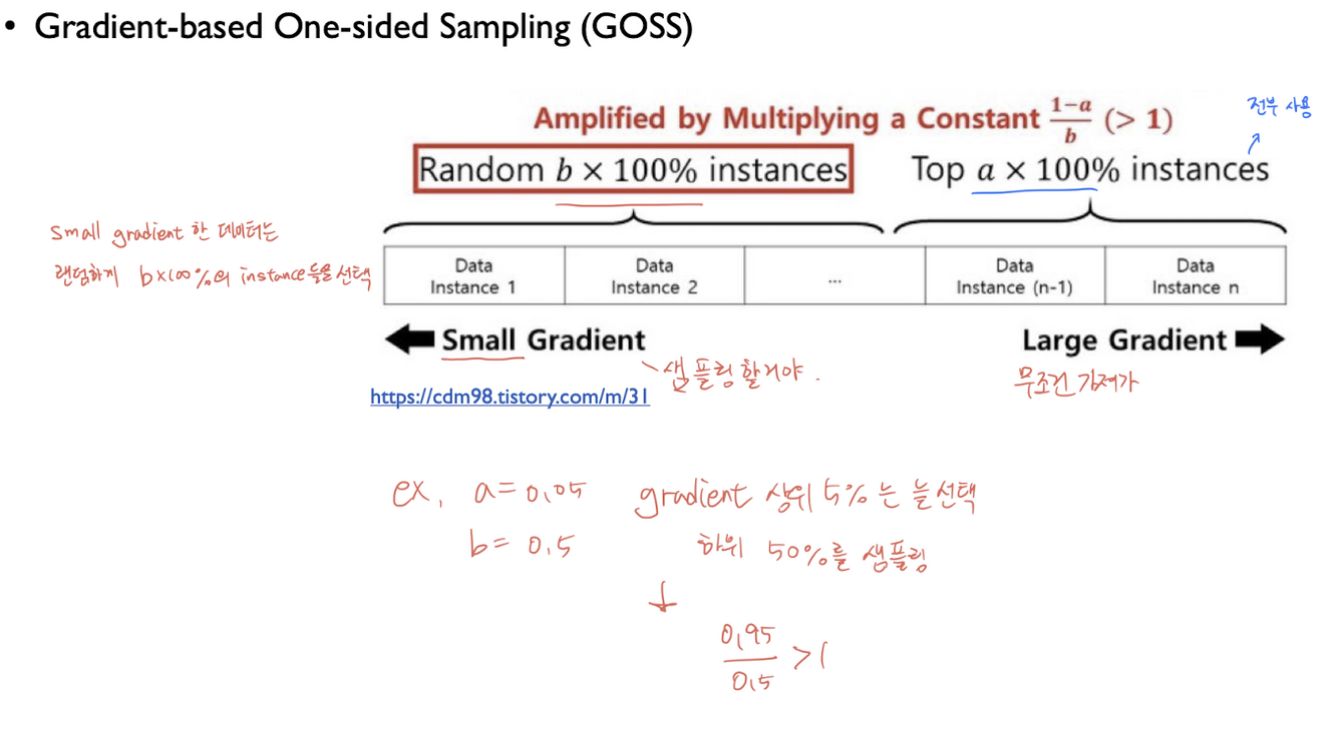
large gradient한 데이터(instances)는 갖고가고, small gradient한 데이터에서 랜덤선택한다. -> 상위몇개를 고정, 하위몇개 중 랜덤하게 골라서 학습한다.
GBDT에서 모든 feature에 대해 스캔을 쭉 해서 가능한 split point를 찾아, information gain을 측정하는데, LightGBM에서는 모든 feature를 스캔하지않기위해, gradient-based One-Side Sampling 를 한다. (GOSS)
GBDT에는 weight는 없지만, gradient가 있다. 따라서 데이터의 개수를 내부적으로 줄여서 계산할 때, 큰 gradient를 가진 데이터는 그대로 사용하고, 낮은 gradient를 랜덤하게 drop하고 데이터를 가져와서, 샘플링을 해준다. gradient가 적다고 버리면 데이터 분포 자체가 왜곡될 수 있기에, 이대로 훈련하면 정확도가 낮아진다.
이를 방지하기위해 가져온 낮은 gradient 데이터에 대하여 ${1-a}\over{b}$ 만큼 뻥튀기 해준다. (a: 큰 gradient데이터 비율, b: 작은 gradient 데이터 비율)
낮은 gradient를 가진 데이터만 drop하므로, One-Side Sampling이라고한다. 이렇게 feature를 줄여서 학습하는 것이다.
topN = a * len(I) ,전체 데이터의 a만큼 index (ex. 100개 중 a=0.2라면 topN=20) randN = b* len(I) ,topN과 비슷하게 b만큼 index
모델로 일단 예측
실제값과의 error로 loss를 계산, weight를 계산하여 저장
loss대로 정렬 -> sorted에 저장. sorted[1:topN] 만큼 Loss 상위 데이터들 topSet에 저장 (ex. 전체 100개 중 a=0.2라면 20개)
나머지 80개 중 randN개 만큼 랜덤샘플링하여 randSet에 저장 (ex. 나머지 80개 중 b=0.2라면 16개 데이터)
UsedSet에 topSet과 randSet을 저장
small gradient data에 fact(=${1-a}\over {b}$)만큼 weight를 부여해줌
weak learner를 만들어서 새로운 모델로 부여 , weak leaner에는 샘플링된 데이터(UsedSet = topSet + fact assigned randSet)와 loss와 weight가 들어감
모델 저장
EFB (Exclusive Feature Bundling)
In a sparse feature space, many features are (almost) exclusive, i,e., they rarely take nonzero values simultaneously (ex. one-hot encoding)
Bundling these exclusive features does not degenerate the performance
하나의 객체(feature)에 대해 특정 두개의 변수가 Non-Zero값을 갖는 경우가 드물다.
그리하여 exclusive한 변수들을 번들링해도 성능저하가 거의 없다.
Greedy Bundling에서는 지금 현재 존재하는 feature set들에 대해서 어떠한 feature들을 하나의 번들로 묶을지 결정
Merge Exclusive Features에서는 번들링되어야하는 변수들을 이용, 하나의 변수로 값을 표현(Merge해줌)
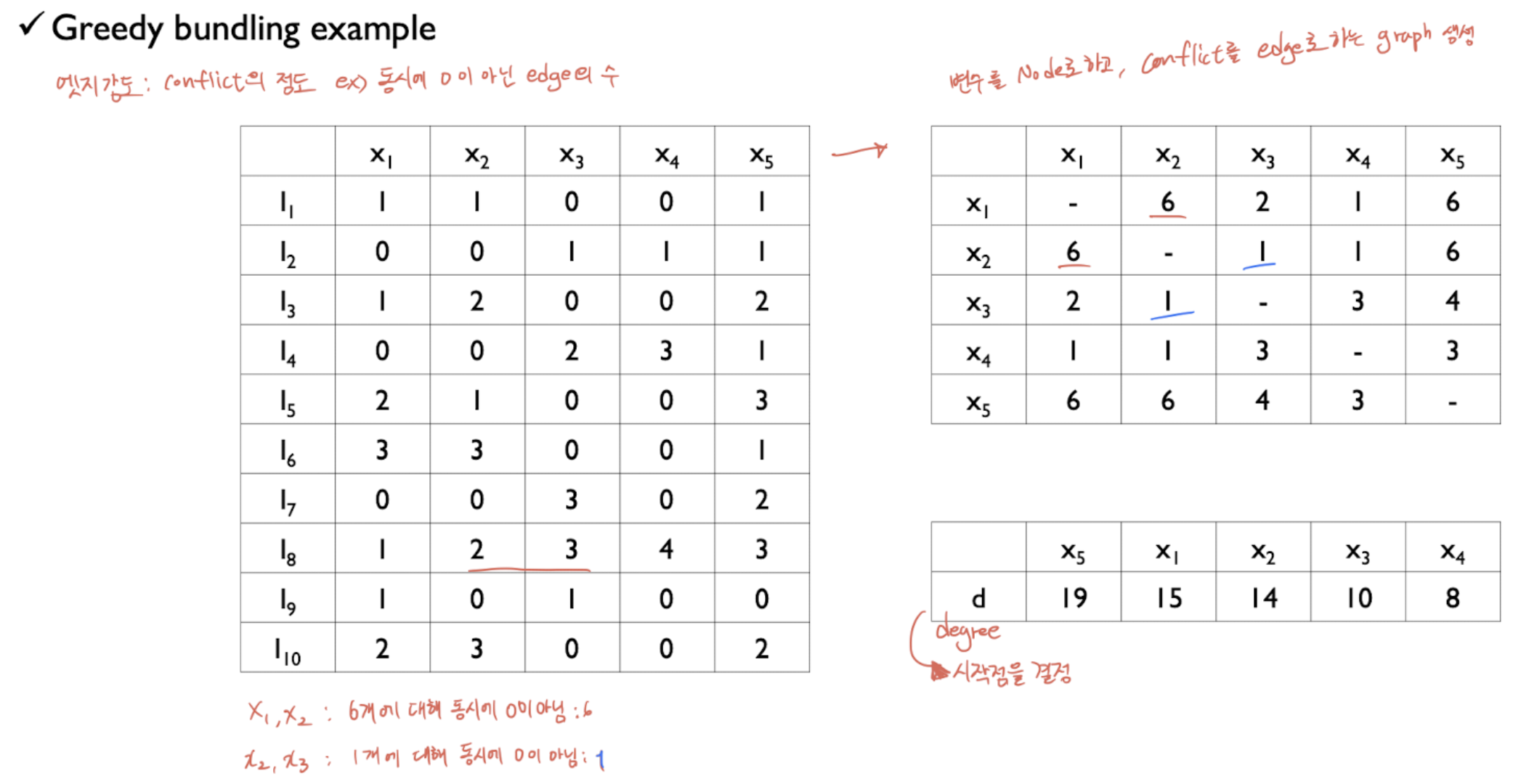
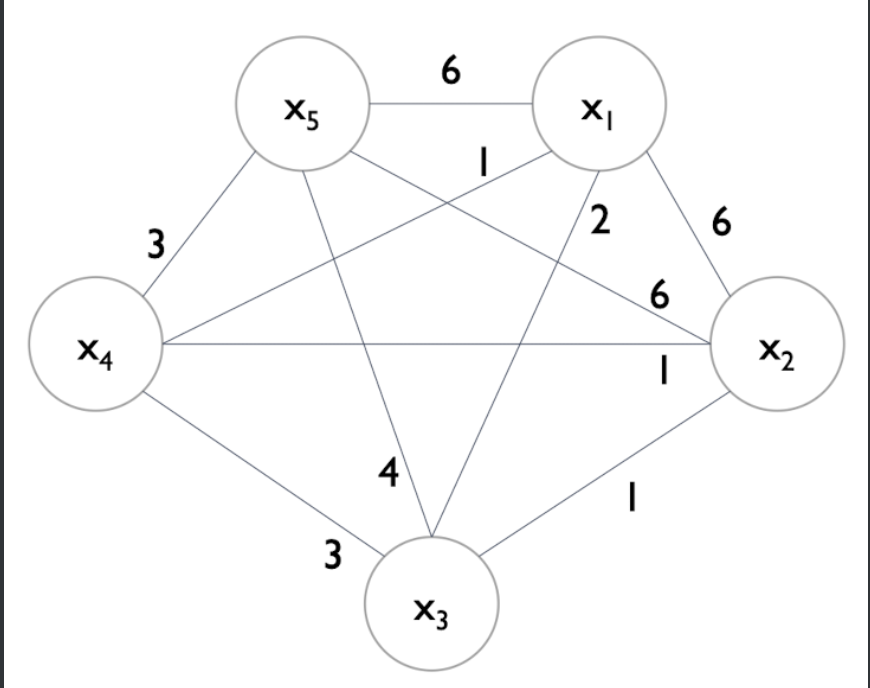
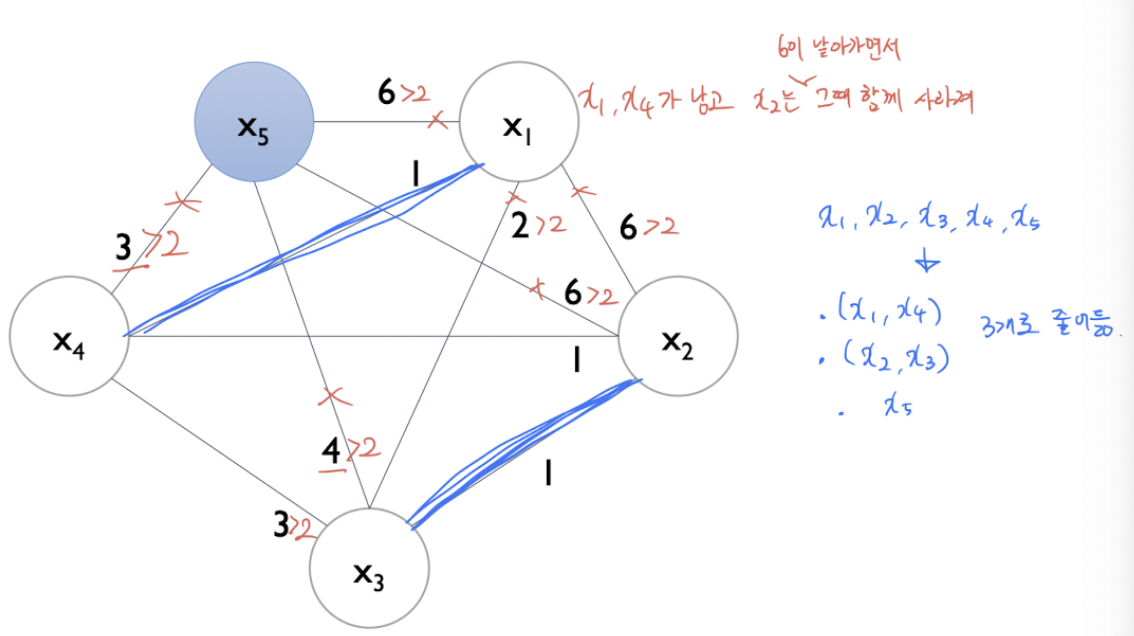
예를들어 이러한 데이터셋(x1~x5) 먼저 각각의 conflict를 Edge로 하는 Graph를 생성한다 (오른쪽 위) 여기서 conflict는 서로 상충하는 데이터 개수(동시에 0이 아닌 데이터 개수)이다. 이를 바탕으로 오른쪽 아래의 Degree를 계산할 수 있고, 이를통해 시작점을 계산한다. 위의 그림에서는 x5부터 시작.
이렇게 그래프에서 x5부터 시작하며, 각각의 edge는 상충하는 데이터 개수(conflict)이다. 여기서 cut-off가 등장하는데, 이를 기준으로, 번들링에서 cut-off만큼 이상의 conflict라면, 하나의 번들로 묶지않는것이다. 위의 데이터에서는 10개 중 cut-off = 0.2로, 2개 이상 conflict 등장하면 엣지날림. x5는 동떨어지게되므로 그대로가고, x1을 계산할 때, x1과 x2는 6의 conflict로 날리고 x3도 날리면, ... x1,x4가 하나의 번들로 묶이게된다. x2를 계산할 때, 이미 번들링된것을 제외하고, x3과 번들로 묶임. 더이상 묶을게 없으므로 종료.
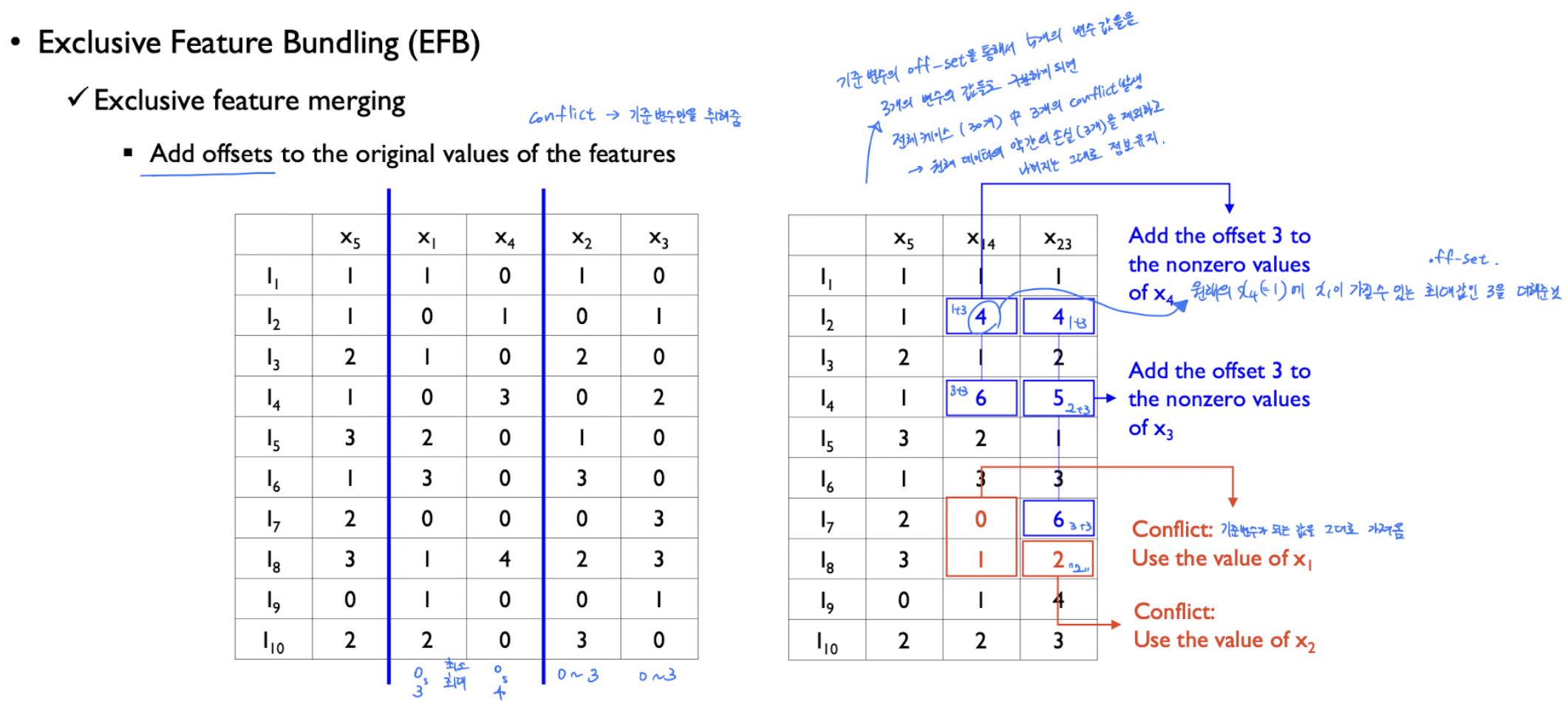
이제 이렇게 묶은 번들에 대하여 Merge Exclusive Features를 진행한다.
각각 column(feature)에 대해 cardinality처럼 최대와 최소값을 기록하고, 기준이 되는 feature에 함께묶인 feature와 merge를 해주는것이다. 이때, 기준값이 있다면 그대로 기준값을 사용하고, 기준값이 없다면, 기준feature의 최대값 + 묶인녀석의 값을 해서 넣게된다. conflict한 경우(둘다 값이 있을 때 or 둘다 0일때) 기준값을 사용한다. (빨강 박스)
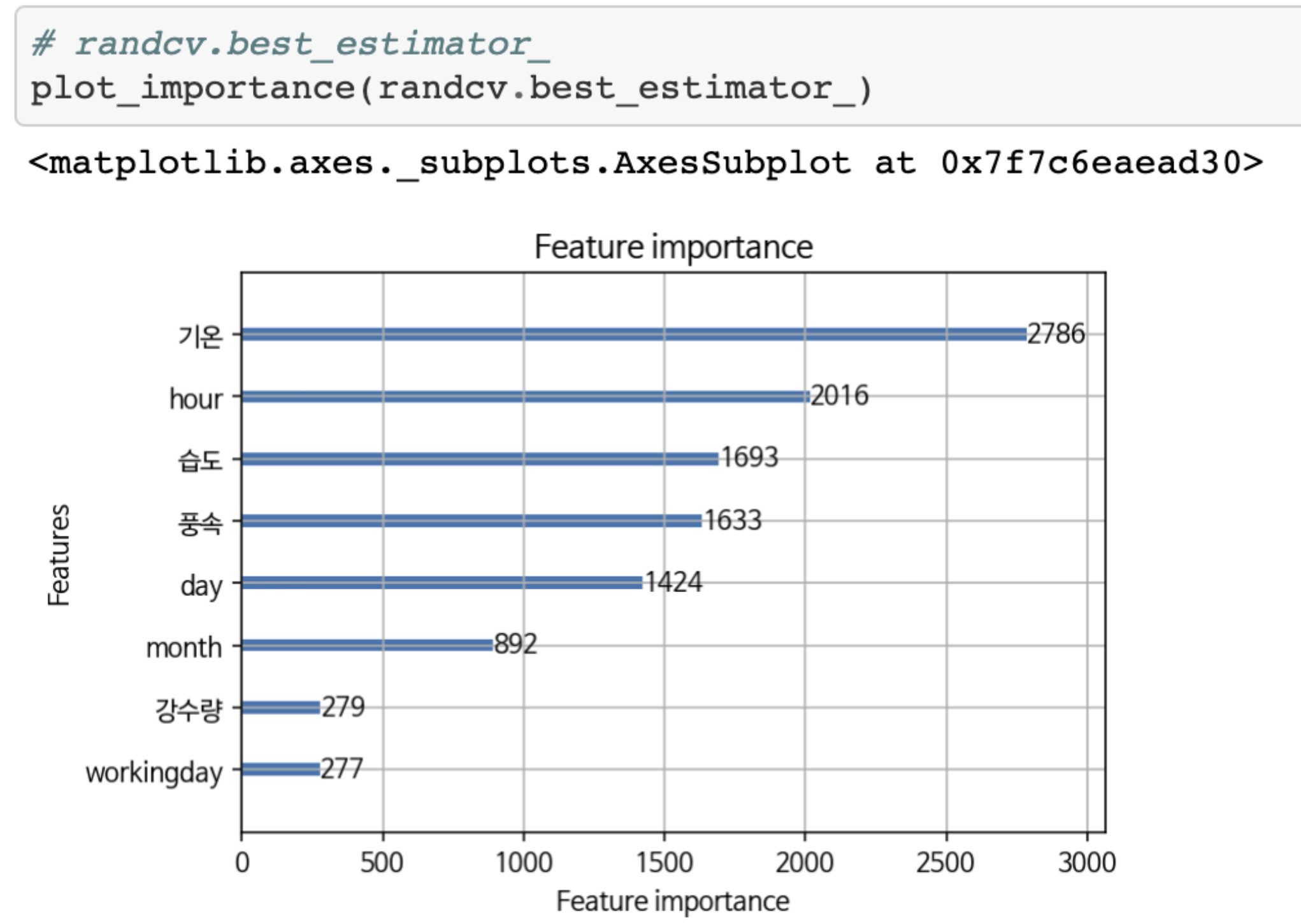
from lightgbm import plot_importance
plot_importance(lgb_model)
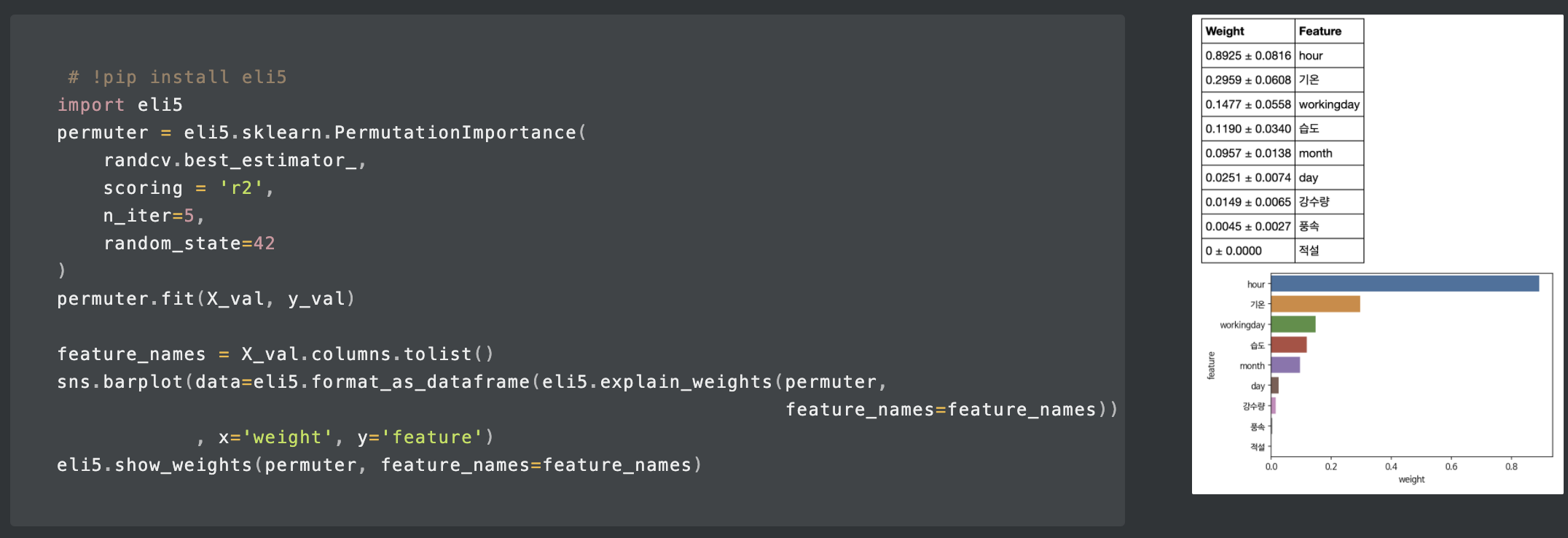
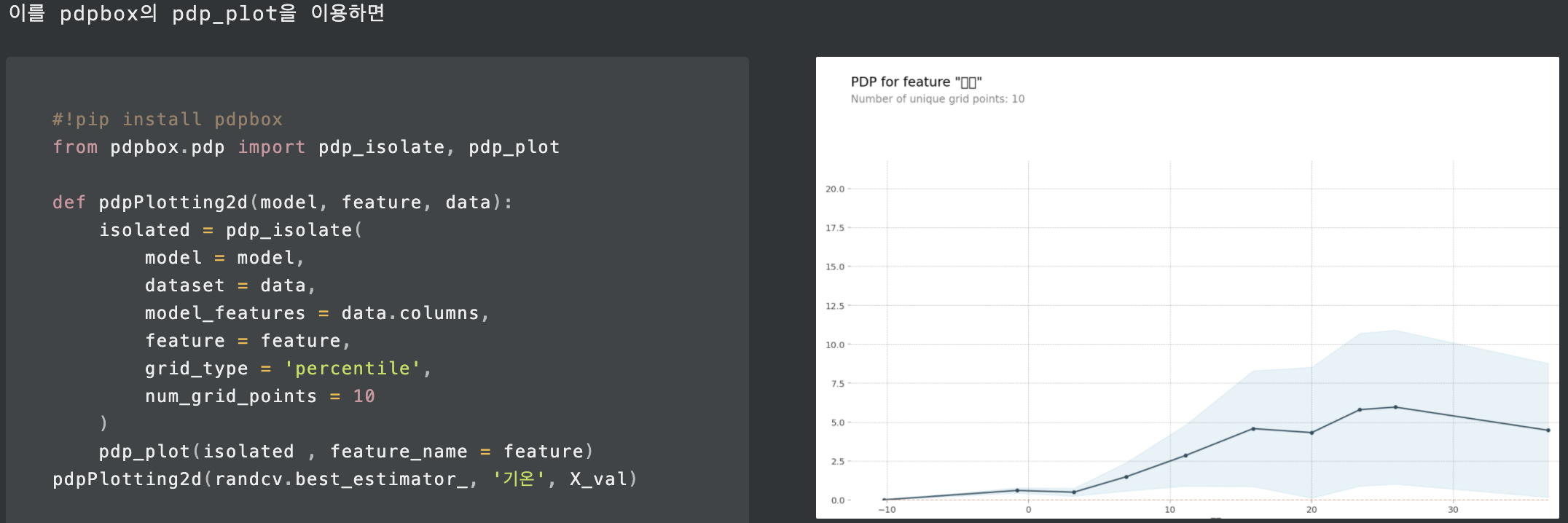
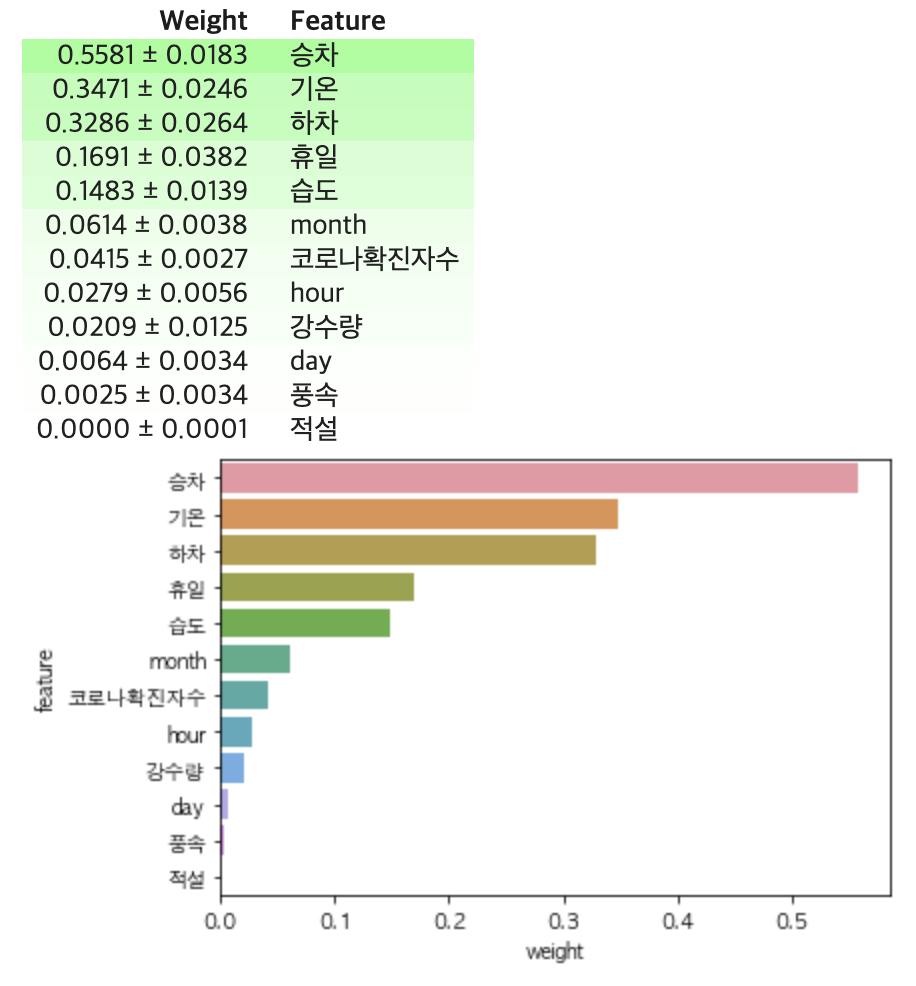
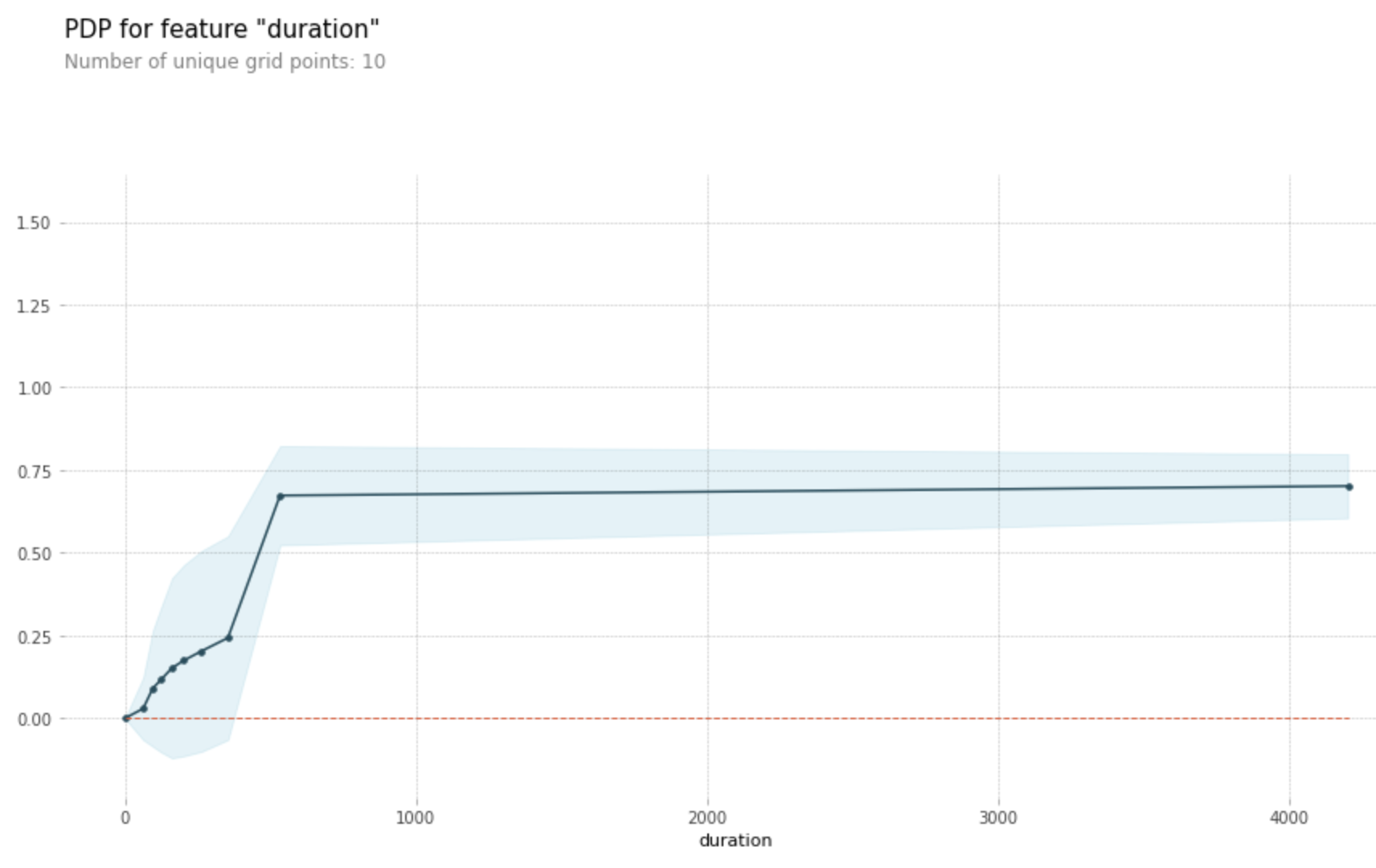
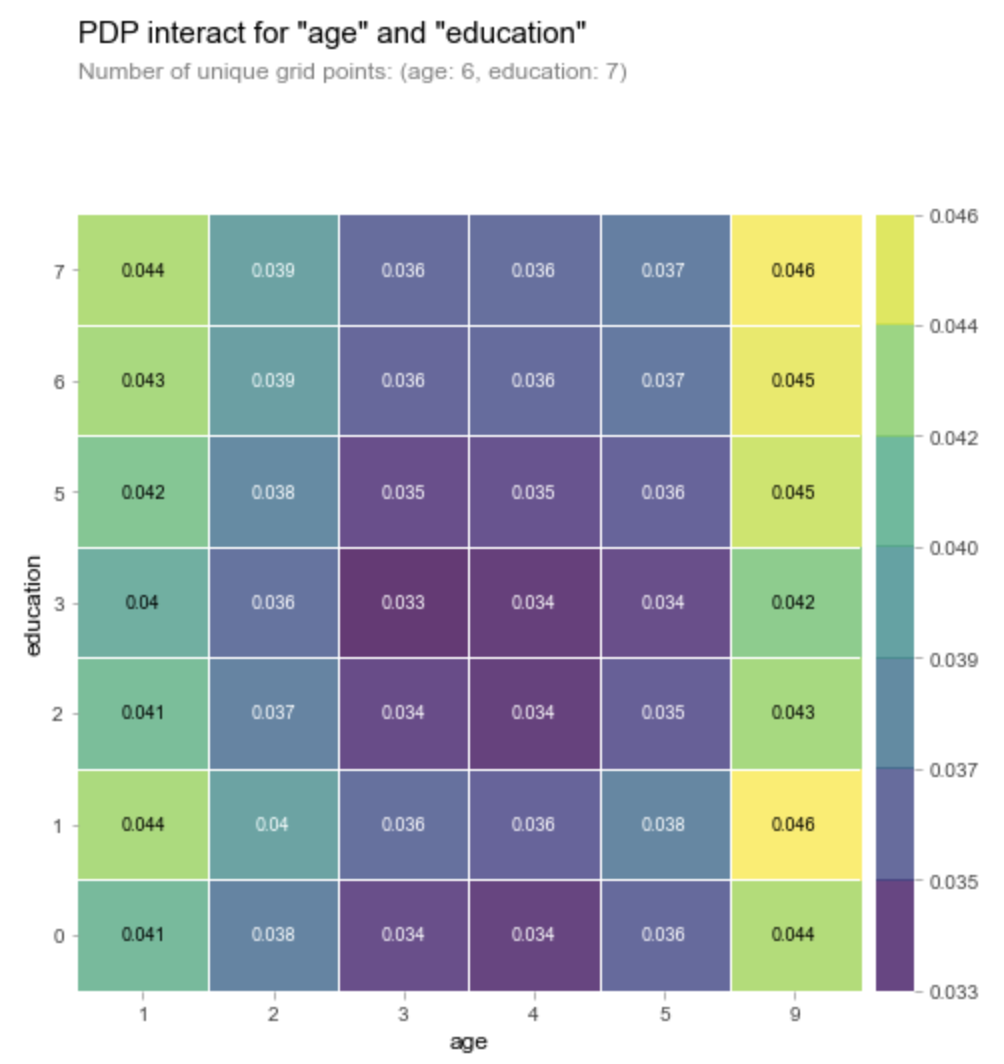
또한, eli5를 통해 Permutation Importance를 볼 수 있고, pdpbox의 pdp_plot, shap으로도 feature_importance를 볼 수 있다.
핵심 파라미터
max_depth : Tree의 최대 깊이를 말합니다. 이 파라미터는 모델 과적합을 다룰 때 사용됩니다. 만약 여러분의 모델이 과적합된 것 같다고 느끼신다면 제 조언은 max_depth 값을 줄이라는 것입니다.
min_data_in_leaf : Leaf가 가지고 있는 최소한의 레코드 수입니다. 디폴트값은 20으로 최적 값입니다. 과적합을 해결할 때 사용되는 파라미터입니다.
feature_fraction : Boosting (나중에 다뤄질 것입니다) 이 랜덤 포레스트일 경우 사용합니다. 0.8 feature_fraction의 의미는 Light GBM이 Tree를 만들 때 매번 각각의 iteration 반복에서 파라미터 중에서 80%를 랜덤하게 선택하는 것을 의미합니다.
bagging_fraction : 매번 iteration을 돌 때 사용되는 데이터의 일부를 선택하는데 트레이닝 속도를 높이고 과적합을 방지할 때 주로 사용됩니다.
early_stopping_round : 이 파라미터는 분석 속도를 높이는데 도움이 됩니다. 모델은 만약 어떤 validation 데이터 중 하나의 지표가 지난 early_stopping_round 라운드에서 향상되지 않았다면 학습을 중단합니다. 이는 지나친 iteration을 줄이는데 도움이 됩니다.
lambda : lambda 값은 regularization 정규화를 합니다. 일반적인 값의 범위는 0 에서 1 사이입니다.
min_gain_to_split : 이 파라미터는 분기하기 위해 필요한 최소한의 gain을 의미합니다. Tree에서 유용한 분기의 수를 컨트롤하는데 사용됩니다.
max_cat_group : 카테고리 수가 클 때, 과적합을 방지하는 분기 포인트를 찾습니다. 그래서 Light GBM 알고리즘이 카테고리 그룹을 max_cat_group 그룹으로 합치고 그룹 경계선에서 분기 포인트를 찾습니다. 디폴트 값은 64 입니다.
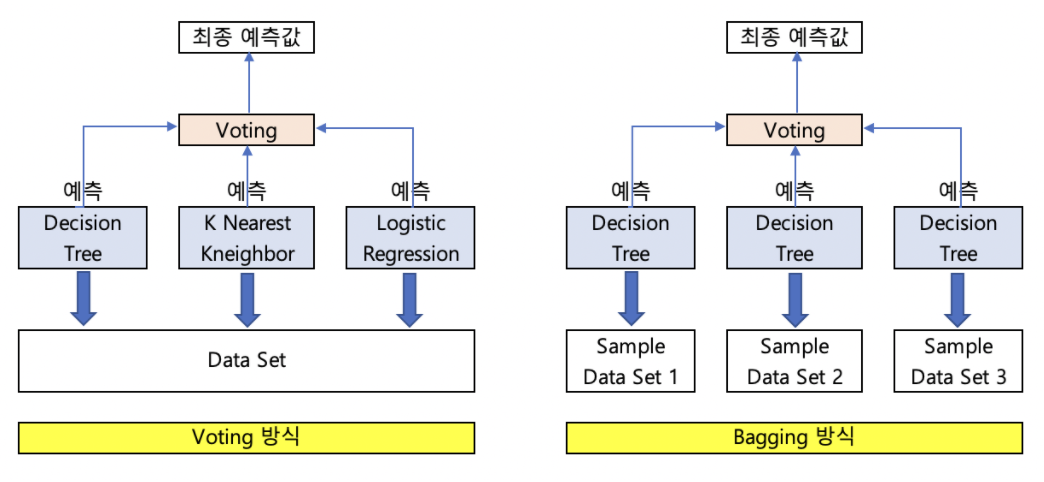
앙상블이랑 여러개의 알고리즘을 사용하여, 그 예측을 결정함으로써 보다 정확한 예측을 도출하는 기법.
기존의 Decision Tree에서 그 트리가 엄청많아져서, 그것들의 최종 값의 비율로 계산하자!
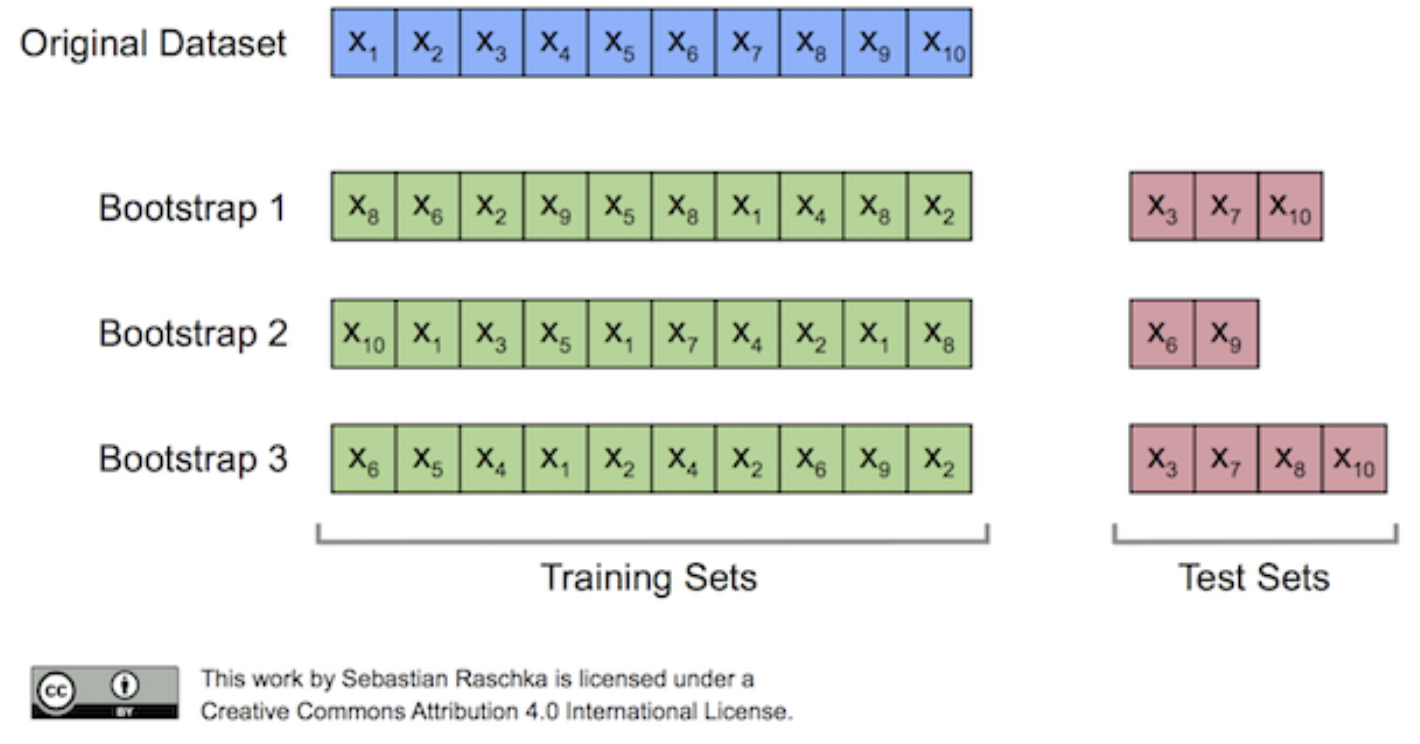
각각 부트스트랩으로 만들어진 데이터셋으로 학습하게되는데, 이를 Bagging (Bootstrap AGGregatING) 이라고 한다.
오리지널 데이터에서 복원추출하는데, 샘플을 뽑고, 다시 원본에서 샘플을 뽑는다. (중복될 수 있다는것) 원본 데이터셋에서 복원추출하는 것을 Bootstrap Sampling이라 한다. 그렇게 samples들을 뽑아서 원본과 같은 수의 sample을 구성하면 그게 부트스트랩샘플을 하나 만들었다고 한다. 각각의 부트스트랩 샘플의 Training set 에서 뽑히지 않은 샘플들을 test set으로 분류하고 이를 OOB Sample이라고 한다. → 100 개 데이터 중 70개로 트레인하고, 나머지 30개로 validation을 매 트리 생성시마다 한다고 보면 됨.
앙상블 기법은 한 종류의 데이터로 여러 학습모델을 만들어, 그 모델들의 예측결과를 다수결이나 펴균을 내어 예측하는 방법을 말한다.
랜덤포레스트는 Decision Tree를 기본모델로 사용한다.
부트스트랩 세트의 크기가 n일 때, 한번의 추출에서 어느 한 샘플이 추출되지 않을 확률은 ${n-1} \over n$ 이다. 그것을 n번 반복였을 때에도 그 샘플이 추출되지 않았을 확률은 $ ({{n-1}\over n})^2$ 이다. 이게 이제 무한히 커지면 어느 한 점으로 수렴하게 되는데.
결과적으로 데이터가 충분할 때 한 부트스트랩 세트는 63.2%의 샘플을 갖고, 여기에 속하지 않은 36.8% 의 샘플이 Out-of_Bag 샘플이며, 이것이 검증에 사용된다.
트리모델에서는 One-hot Encoding보다 Ordinal Encoding이 좀더 성능이 좋을 때가 많다. 원핫으로 피쳐가 추가되었을 때, 트리에서는 상위노드에서 중요한 피처가 사용되므로, 하나의 피쳐가 여러개의 피쳐로 쪼개진 One-Hot에서 범주 종류가 많은 (High Cardinality) 피쳐였을 경우 상위노드에서 선택될 가능성이 적어진다.
n_estimators = 트리의 갯수 | number of trees in the foreset
max_features = 노드들 구분할 때 고려할 최대 피쳐수 | max number of features considered for splitting a node
max_depth = 각 트리의 최대 깊이 | max number of levels in each decision tree
min_samples_split = 최소 분할 샘플 갯수 | min number of data points placed in a node before the node is split
min_samples_leaf = 최소 잎 노드 데이터 수 | min number of data points allowed in a leaf node
bootstrap = 복원 추출 | method for sampling data points (with or without replacement)
랜덤 포레스트의 Pseudo Code
S는 트레이닝셋, Feature 는 F, 랜덤포레스트 안의 트리는 B 라고 한다. H를 초기화하고, 1부터 B까지 (트리들을 순회하면서), $S^(i)$ 에 S로 부터 만든 부트스트랩 샘플을 넣고, $h_i$ 에 트리를 학습시키고(트리의 학습은, 각각의 노드에서 feature의 subset을 최적으로 쪼개면서 학습시킨다. ), 이후, 학습된 트리들 하나하나를 H에 합친 후, 최종 H를 리턴.
from sklearn.model_selection import train_test_split
train, val = train_test_split(train, train_size=0.8, test_size=0.2,
stratify=train[target], random_state=2)
##############################################
from category_encoders import OrdinalEncoder
from sklearn.pipeline import make_pipeline
pipe_ordinal_simple=make_pipeline(verbose=0,
OrdinalEncoder(verbose=0),
SimpleImputer(),
RandomForestClassifier(n_jobs=-1, random_state=10, oob_score=True)
)
pipe_ordinal_simple.fit(X_train,y_train)
pipe_ordinal_simple.score(X_val,y_val) #0.8258806784485826
ㅇ 이렇게 파이프라인속에 넣어서 사용할 수도 있다. X_train으로 fit(학습)시키고, X_val로 분리해놓은 데이터를 통하여 점수를 매겨보는 등의 작업을 하면된다.
하이퍼파라미터 튜닝
n_estimators = 트리의 갯수 |number of trees in the foreset
max_features = 노드들 구분할 때 고려할 최대 피쳐수 |max number of features considered for splitting a node
max_depth = 각 트리의 최대 깊이 |max number of levels in each decision tree
min_samples_split = 최소 분할 샘플 갯수 |min number of data points placed in a node before the node is split
min_samples_leaf = 최소 잎 노드 데이터 수 |min number of data points allowed in a leaf node
bootstrap = 복원 추출 |method for sampling data points (with or without replacement)
class_weight = sample의 라벨 비율 -> 기존의 분류문제에서 라벨비율이 비슷하지 않으면, 좋지 않은 학습결과를 가져올 수 있는데, 이를 처리해줌.
class_weight 설정
어떠한경우 target 의 class 비율이 다를 수 있다. 이는 모델 학습에 악영향을 끼치는데, 이 부분에 대하여 RandomForest에서는 class_weight라는 파라미터를 준다.
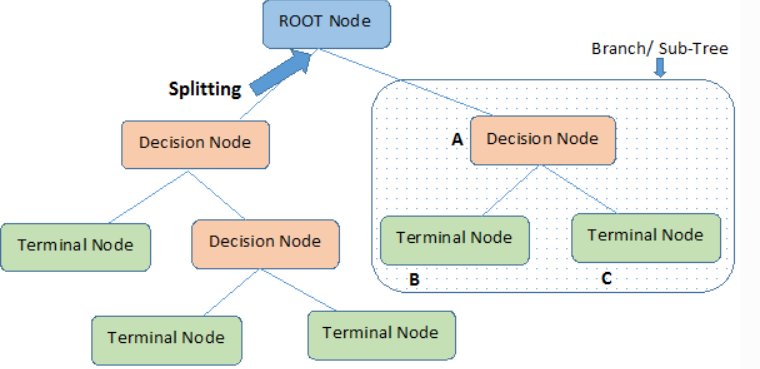
결정트리모델은 특성들을 기준으로 샘플을 분류해 나가는데, 마치 Tree model처럼 뻗어나간다고해서 Decision Tree라는 이름을 갖는다.
결정트리는 학습 결과로 IF-THEN 형태의 규칙이 만들어진다.
결정트리는 퍼셉트론이나 로지스틱 회귀와 달리 선형 분리 불가능한 데이터도 분류할 수 있으나, 선형분리 가능한 문제는 잘 풀지 못한다. 또한 데이터를 조건 분기로 나눠가는 특성상, 트리가 깊어질수록 학습에 사용되는 데이터 수가 적어져 과적합을 일으키기 쉽다.
결정 트리는 학습 데이터로부터 조건식을 만들고, 예측할 때는 트리의 루트(최상위조건)부터 순서대로 조건분기를 타면서 리프에 도착하면 예측결과를 내는 알고리즘이다.
불순도(Impurity)를 기준으로 가능한 한 같은 클래스끼리 모이도록 조건 분기를 학습한다.
구체적으로는 정보획득(Information Gain)이나 지니게수(Gini Coefficient)등의 값을 불순도로 사용해, 그 값이 낮아지도록 데이터를 분할한다.
이후 결정트리가 응용되어 랜덤포레스트와 경사부스팅결정트리가 생겨났다.
결정트리의 각 노드는 뿌리, 중간, 말단 노드로 나뉠 수 있다.
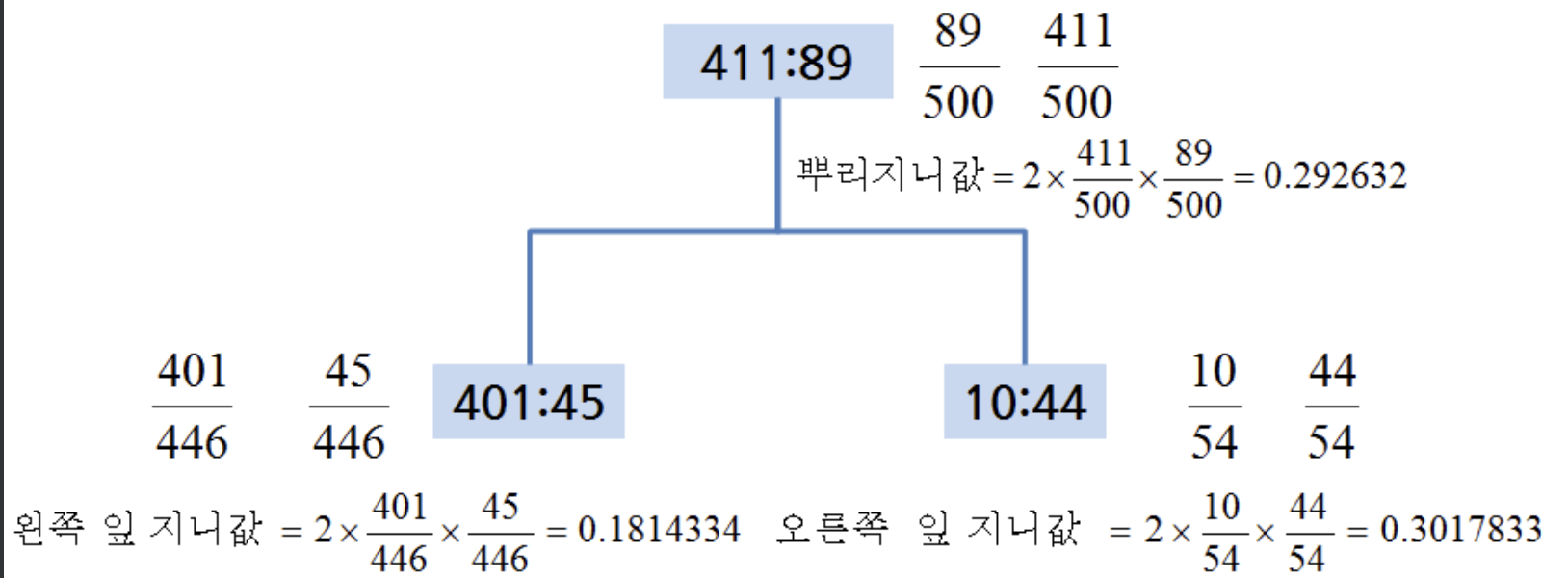
지니불순도
※ 지니계수 : 경제학에서 불평등지수를 나타낼 때 사용하는 것으로 0일 때 완전 평등, 1일 때 완전 불평등을 의미합니다.
머신러닝에서는 데이터가 다양한 값을 가질수록 평등하며 특정 값으로 쏠릴 때 불평등한 값이 됩니다. 즉, 다양성이 낮을수록 균일도가 높다는 의미로 1로 갈수록 균일도가 높아 지니계수가 높은 속성을 기준으로 분할
임의의 새로운 변수가 데이터셋으로부터 클래스 라벨의 분포를 따라 무작위로 분류된 경우, 임의 변수의 새로운 인스턴스의 잘못된 분류 가능성에 대한 측정치. 분류가 잘 되었는지 판단할 수 있는 척도이다. $G_i = {1 - \Sigma_{k=1}^n{p_ik^2} }$
$I_G(p) = \Sigma_{i=1}^J{p_i ( 1-p_i) } = 1 - \Sigma_{i=1}^J{p_i^2} $ 정보획득은 특정한 특성을 사용해 분할했을 떄 엔트로피의 감소량을 뜻한다.
여기서 불순도(impurity) 라는 개념은 여러 범주가 섞여 있는 정도를 이야기 한다. 예를들어 A, B 두 클래스가 혼합된 데이터가 있을 때 (A, B) 비율이 (45%, 55%)인 샘플(두 범주 수가 비슷)은 불순도가 높은 것이며 (80%, 20%)인 샘플이 있다면 상대적으로 위의 상태보다 불순도가 낮은 것 입니다. (순수도(purity)는 높음)
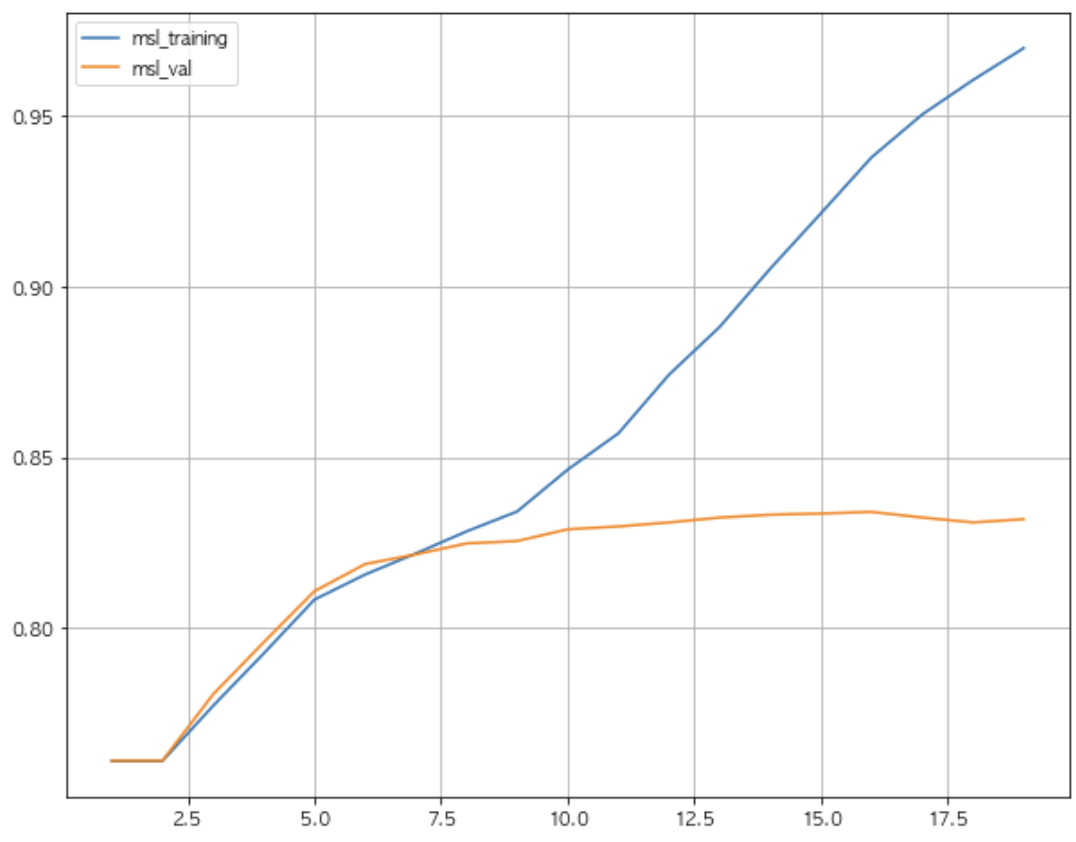
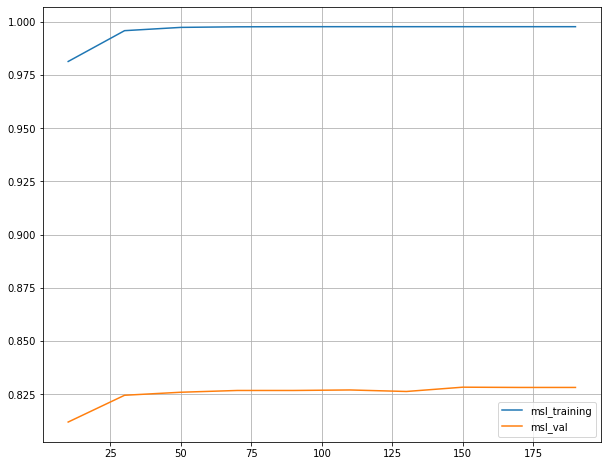
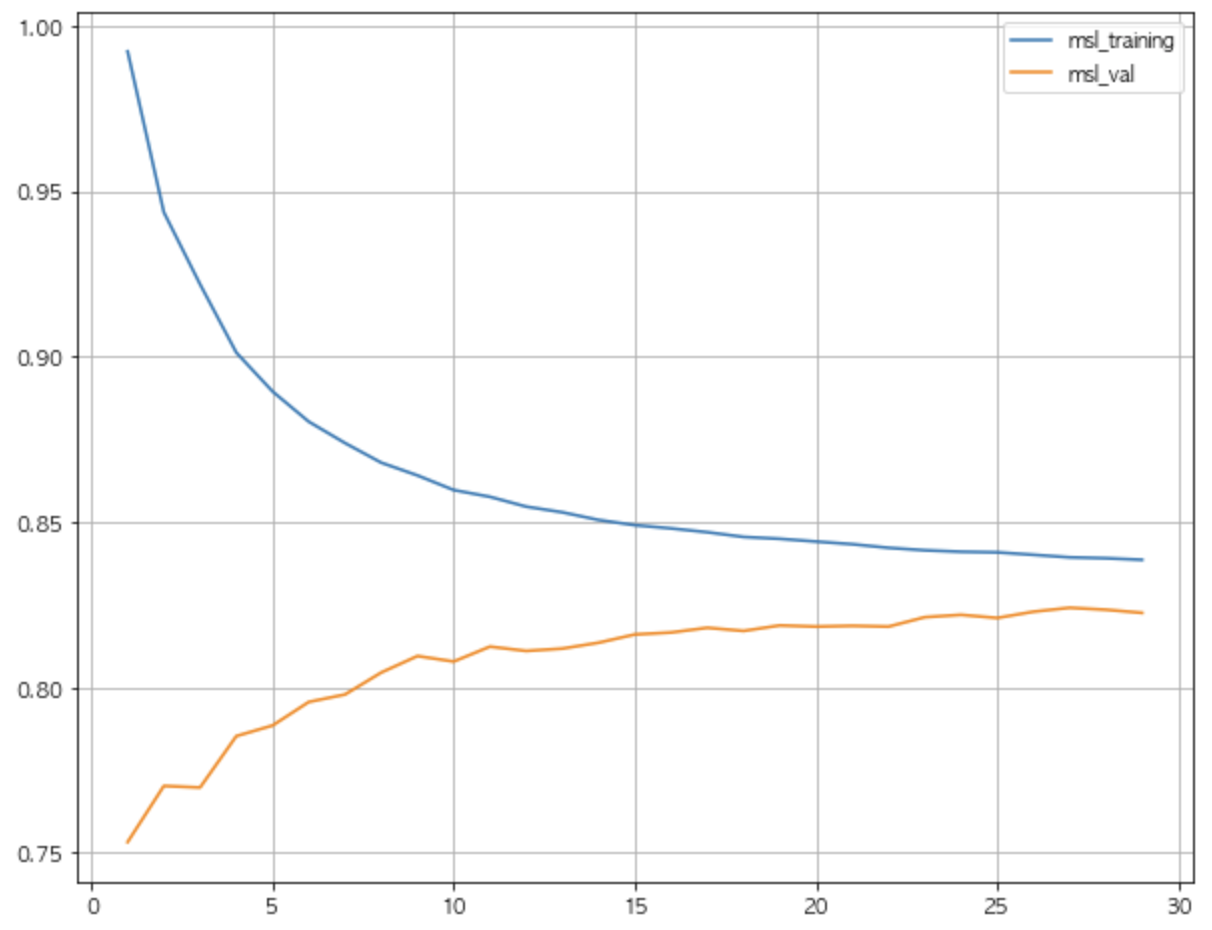
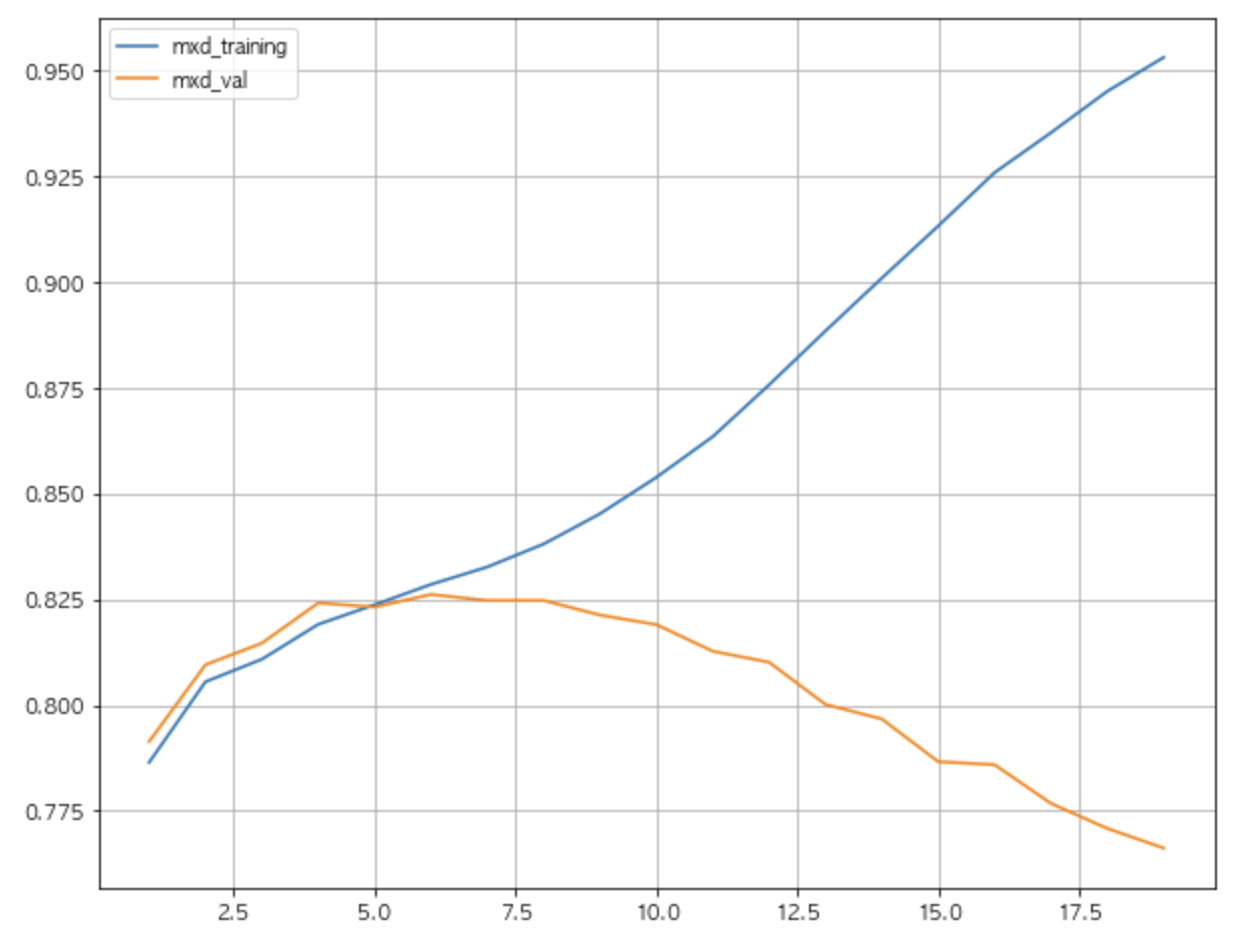
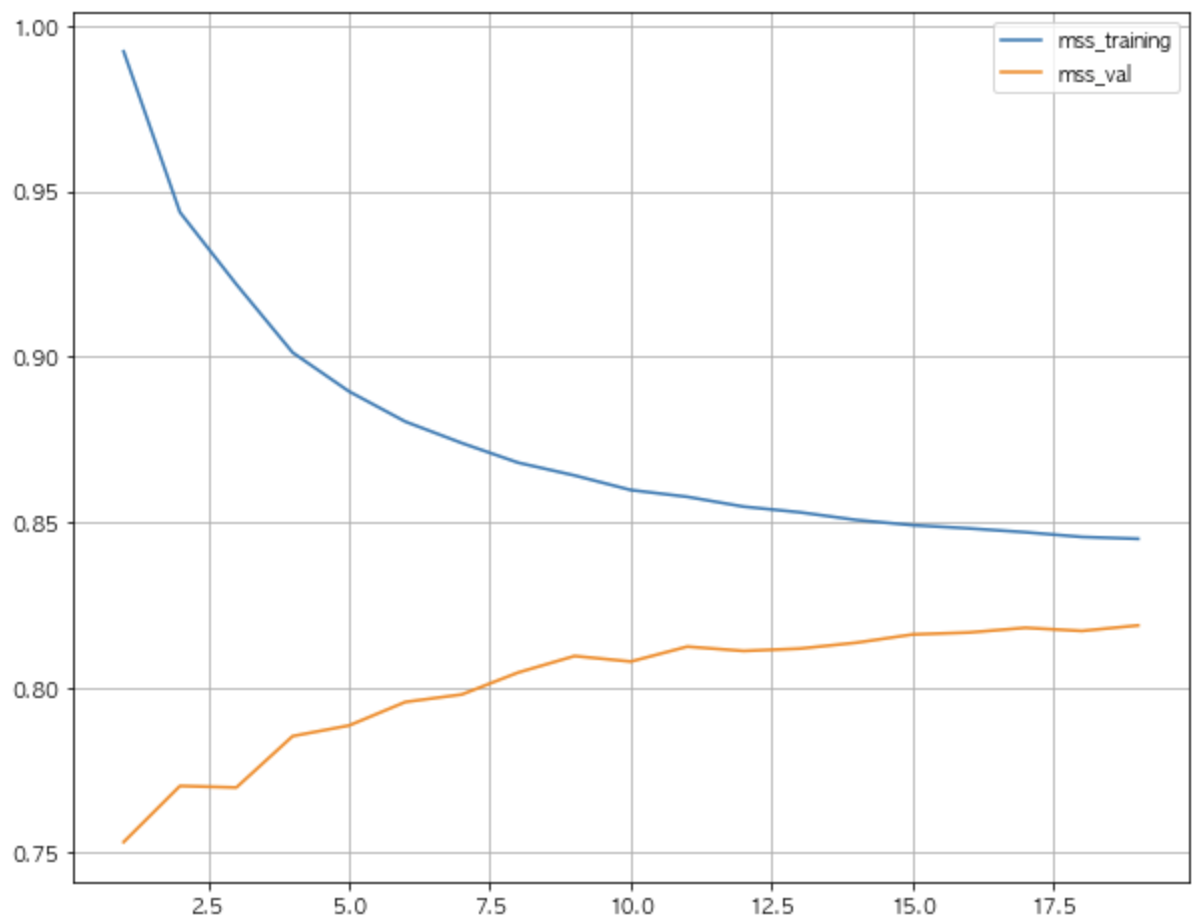
max_depth 는 트리의 최대 깊이를 나타냅니다. default 는 None으로 완벽하게 클래스 값이 결정될때까지 or min_samples_split보다 작아질 때 까지 분할합니다. 깊이가 깊어질 수록 과적합될 가능성이 높아집니다. training데이터의 경우 깊이가 깊어질수록 정확도가 한없이 증가하는 모습을 보입니다. 하지만 validation데이터의 경우 깊이가 깊어질 수록 정확도가 떨어지는 모습을 보입니다. 해당 depth에 맞게 training데이터가 학습(fit)된 이후, validation데이터가 해당 트리를 통해 걸러져서 분류된 결과가 depth가 깊어짐에 따라 점점 안맞게 된다는 뜻으로 해석됩니다.
min_samples_split 를 높여서 데이터가 분할하는데 필요한 샘플 데이터의 수를 높이기
The minimum number of samples required to split aninternal node: 규칙노드(내부노드)의 분기를 위한 최소 샘플 개수를 지정하는 방식입니다. 기존의 디폴트값은 2로, 어떤 하나와 다른 하나가 나타나는 순간 그 지점에서 분기를 하는반면, 값이 커질수록 다른 n개의 sample이 나타나야 분기를 하는것으로, 분기하는 정도가 조금 더 약해진다고 볼 수 있습니다.
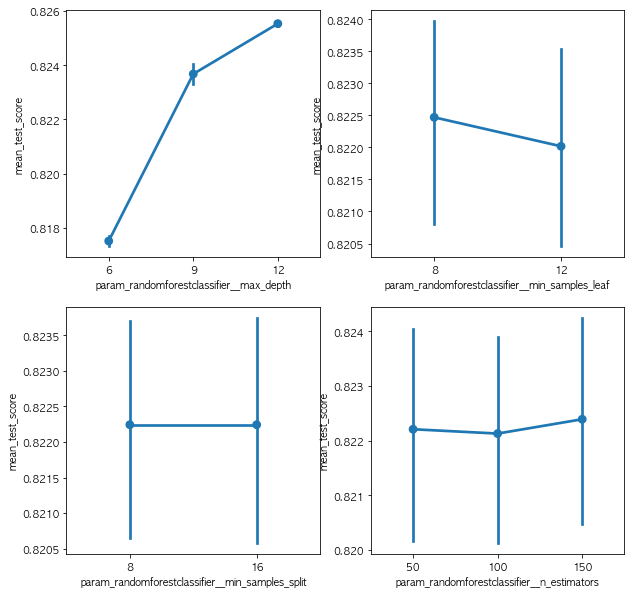
GridSearchCV를 사용해서 params의 조합을 통하여 엄청난 연산을 수행 끝에 거의 5분~10분만에 끝났습니다. 최고 스코어는 : 0.8244818005868766 그 때의 조합 : {'max_depth': 7, 'min_samples_leaf': 14, 'min_samples_split': 10} 이 조합이 기존에 Pipeline으로 하던 것에서 최상의 조합이라고 볼 수 있습니다. (지금까지는.. 아마 나중에 뭔가 다른방법을 알게된다면 시도해보겠습니다.)
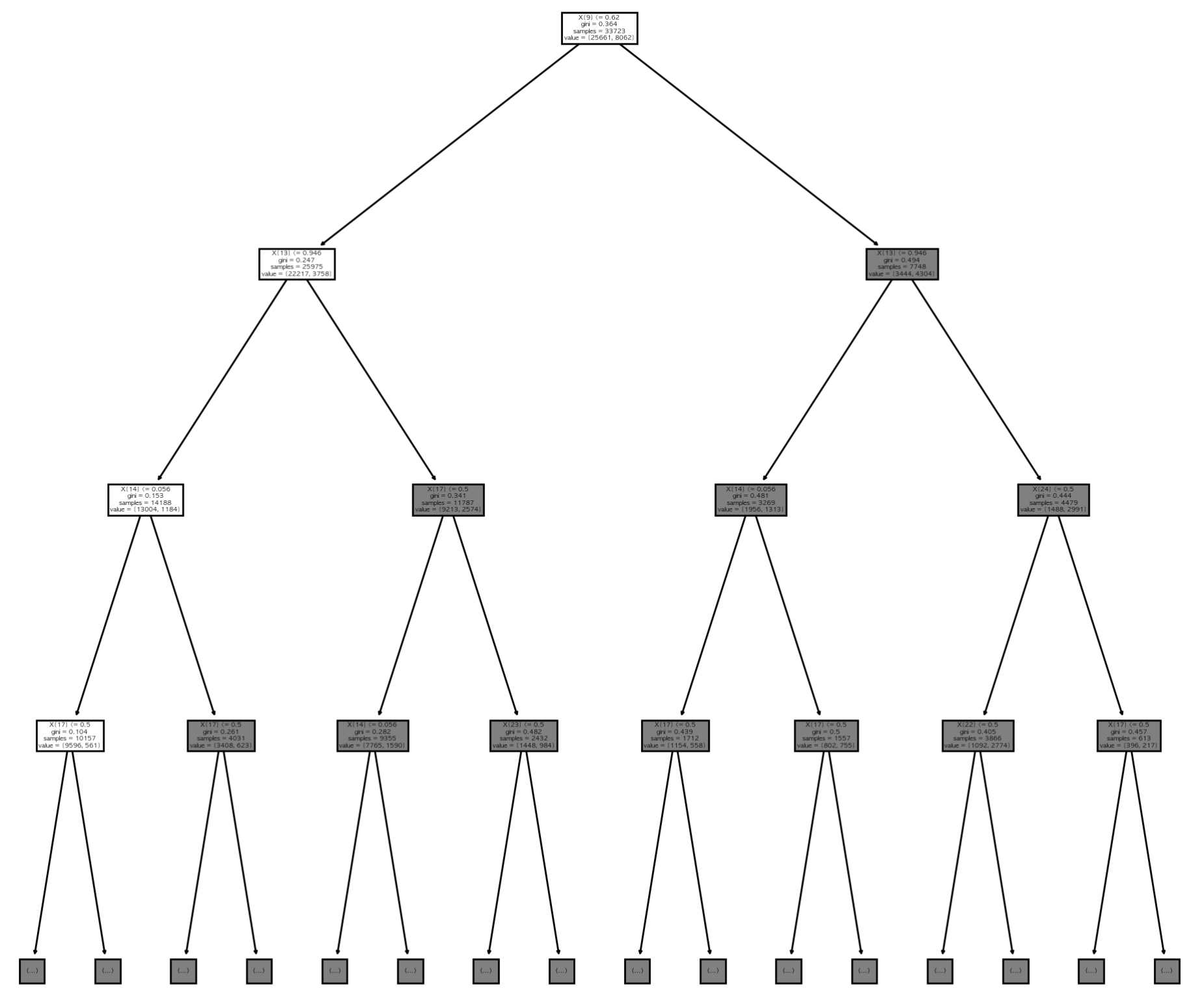
from sklearn import tree
gridbest = gridCV.best_estimator_
plt.figure(figsize=(12,12), dpi=200)
tree.plot_tree(gridbest,max_depth=3);
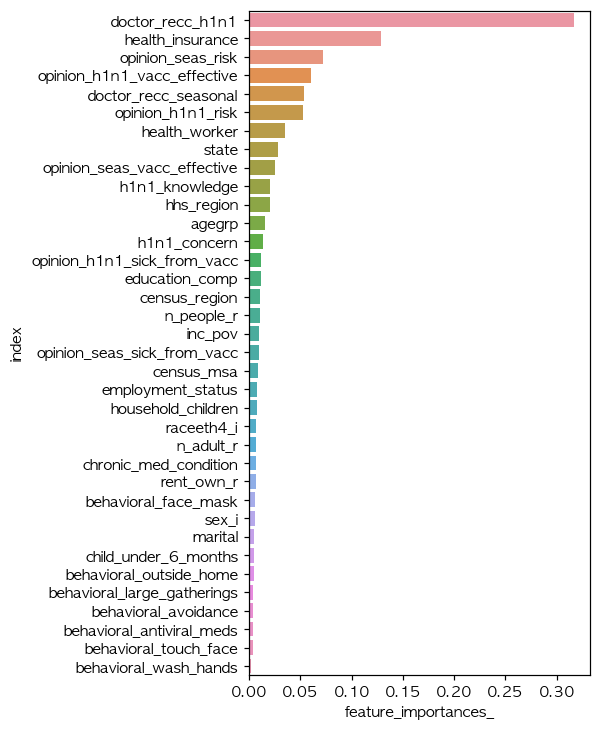
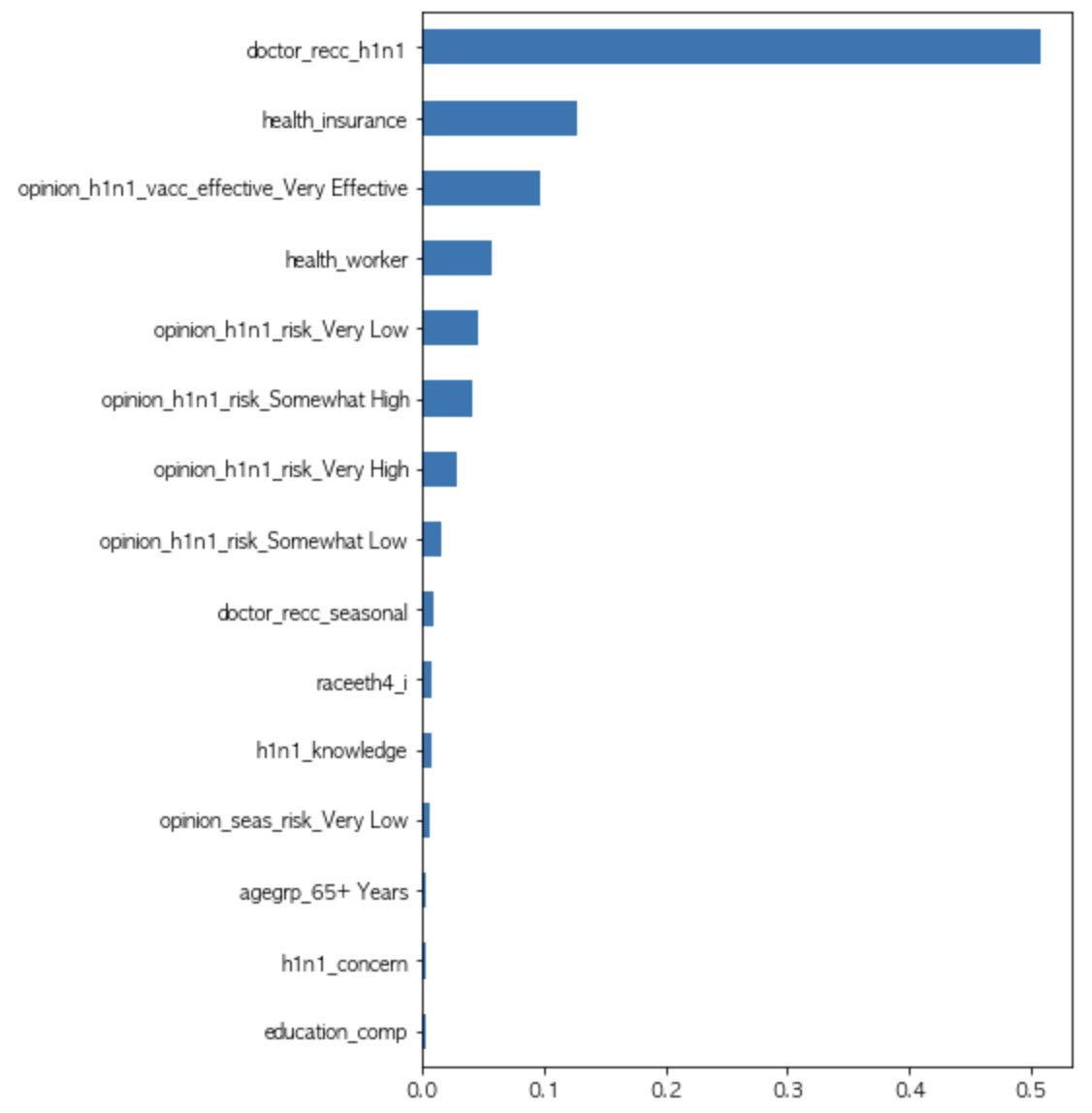
각 columns의 중요도 시각화 doctor_recc_h1n1 의사의 권유가 있었다는 feature가 중요성이 높았고, 그 다음 건강보험 유무였는데, 이 두 변수 사이에 작은 상관관계가 있을것으로 추정됩니다. 그 이유는 보험있는사람들이 병원에 좀더 자유롭게 (가격부담없이) 진료받으러 갔을것이며, 또한 보험이 있기에 백신접종 또한 권유를 더 잘받지않았을까? 또한, 세번째 피쳐가 백신이 효과적이라고 생각하는것 네번째가 의료종사자, 다섯번째는 백신위험이 적다는의견입니다.
유의수준을 통해 결정하는데, 이를 만족하지 못하면 선택되지 않음 → 전부 선택되지 않을수도있음!
$S$를 기존모형에 포함된 변수들의 집합, $\tilde S$를 모형에 포함되지 않은 변수집합 이라 하고 유의수준을 $\alpha$ 라 하자.
아직 모형에 적합시키지 않은 변수 ( $X_k \in \tilde S$ ) 를 기존 모형에 적합. (기존모형의 변수 + $X_k$ 를 통해 모형생성)
이때 최소 p-value 값과 유의수준을 비교하여 p-value < $\alpha$ 이면 최소 p-value에 해당하는 변수를 S에 포함, 1~2 단계 수행
# 참조 : https://zephyrus1111.tistory.com/65
## 전진 선택법
variables = df.columns[:-2].tolist() ## 설명 변수 리스트
y = df['Survival_Time'] ## 반응 변수
selected_variables = [] ## 선택된 변수들
sl_enter = 0.05
sv_per_step = [] ## 각 스텝별로 선택된 변수들
adjusted_r_squared = [] ## 각 스텝별 수정된 결정계수
steps = [] ## 스텝
step = 0
while len(variables) > 0:
remainder = list(set(variables) - set(selected_variables))
pval = pd.Series(index=remainder) ## 변수의 p-value
## 기존에 포함된 변수와 새로운 변수 하나씩 돌아가면서
## 선형 모형을 적합한다.
for col in remainder:
X = df[selected_variables+[col]]
X = sm.add_constant(X)
model = sm.OLS(y,X).fit()
pval[col] = model.pvalues[col]
min_pval = pval.min()
if min_pval < sl_enter: ## 최소 p-value 값이 기준 값보다 작으면 포함
selected_variables.append(pval.idxmin())
step += 1
steps.append(step)
adj_r_squared = sm.OLS(y,sm.add_constant(df[selected_variables])).fit().rsquared_adj
adjusted_r_squared.append(adj_r_squared)
sv_per_step.append(selected_variables.copy())
else:
break
위와같은 식으로 전진선택법을 사용할 수 있으며, 그 외 후진선택법 등이 있다. 이는 코드블럭내의 블로그를 가면 자세히 설명되어있으니 그곳에서 읽어보는것이 더욱 도움될것이다.
sklearn.feature_selection.SelectKBest
사이킷런에서는 SelectKBest라는 모듈을제공하여, Feature Selection을 더욱 간편하게 해준다. 가장 성능이 좋은 변수만 선택해주며, K 라는 파라미터를 통하여, 몇개의 feature를 선택할 지 고를 수 있다.
이 예에서 로트크기와 같이 영향을 주는 변수를 독립변수(explanatory variable), 설명변수(independent variable)라고 하며, 생산인력과 같이 영향을 받는 변수를 종속변수 (dependent variable) 또는 반응변수(response variable) 라고 한다.
회귀분석은 설명변수의 값으로부터 종속변수의 값을 에측하고자 함이 그 목적으로서, 설명변수와 종속변수의 관계를 구체적인 함수 형태로 나타내고자 하는 것이 분석의 주요 내용이다.
설명변수가 한 개일 때의 회귀분석을 단순 회귀분석 (simple regression)이라 하고, 두 개 이상의 설명변수를 고려하는 회귀분석을 multiple regression이라 한다.
설명변수가 하나이고 설명변수와 종속변수의 관계가 직선관계인 경우 Simple Linear Regression이라 한다.
회귀분석의 첫 단계에서 할 일은 산점도를 그려보고, 독립변수와 종속변수의 관게에 대한 대략적인 파악을 하고, 적절한 모형을 설정하는 것이다.
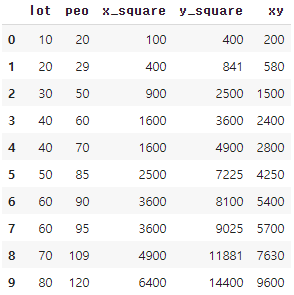
df['x_square'] = df['lot'].apply(lambda x : x**2)
df['y_square'] = df['peo'].apply(lambda x : x**2)
df['xy']=df[['lot','peo']].apply(lambda x : x['lot'] * x['peo'], axis=1)
df
def simpleLinearRegression(x,y):
# input : two list x and y (x and y must have same length)
# output : alpha, beta ( y = alpha + beta * x )
meanx=sum(x)/len(x)
meany=sum(y)/len(y)
분자=sum(list(map(lambda x : (x[0]-meanx)*(x[1]-meany),zip(x,y))))
분모=sum(list(map(lambda x : (x-meanx)**2 , x)))
beta=분자/분모
alpha=meany - beta*meanx
print(f"y = {beta} * x + ({alpha})")
return alpha, beta
simpleLinearRegression(df['lot'],df['peo'])
y = 1.4801801801801804 * x + (4.7117117117117004)
(4.7117117117117004, 1.4801801801801804)
'''