eli5
Permutation Importance
각 특성의 값을 random하게 변형을 하고, 그 때 얼마나 error가 커지는지를 기준으로 각 특성의 중요도를 산출
!pip install eli5
import eli5
permuter = eli5.sklearn.PermutationImportance(
xgbr, ## 이미 학습이 완료된 모델
scoring = 'r2',
n_iter=5,
random_state=42
)
permuter.fit(X_val, y_val)
feature_names = X_val.columns.tolist()
sns.barplot(data=eli5.format_as_dataframe(eli5.explain_weights(permuter, feature_names=feature_names)), x='weight', y='feature')
eli5.show_weights(permuter, feature_names=feature_names)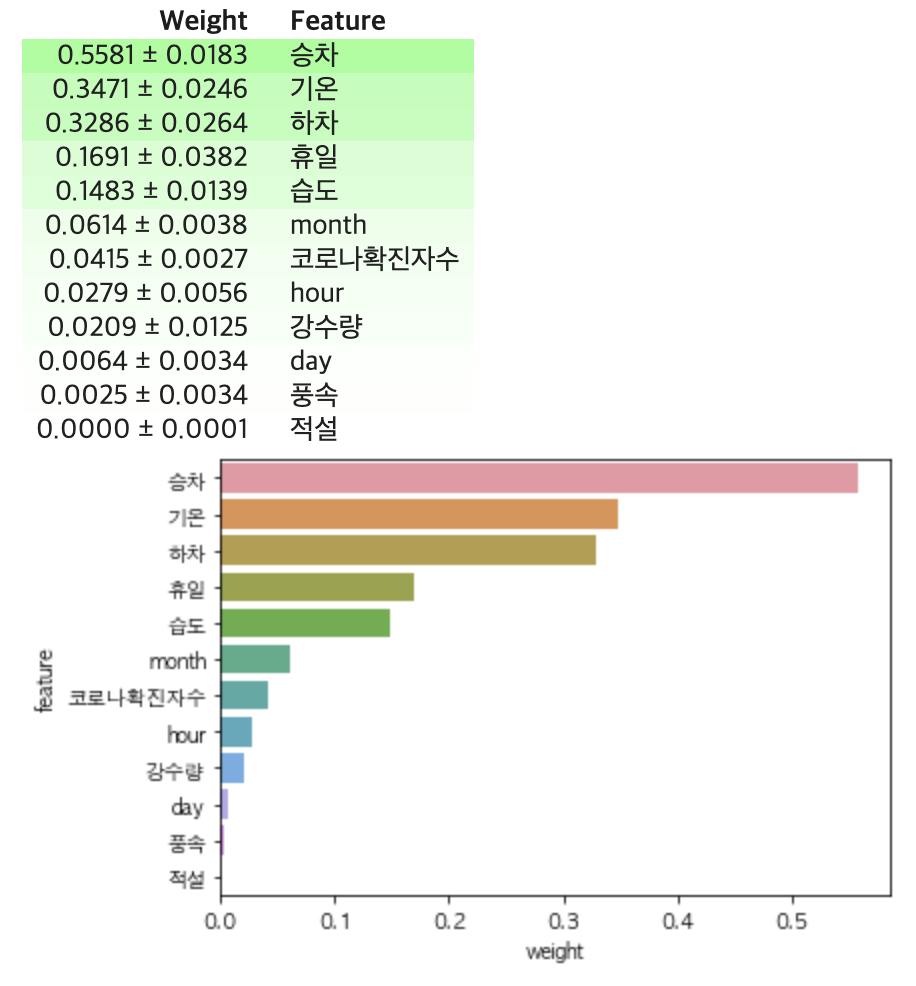
pdpbox
Ensemble모델을 만들었을때 가장 큰 문제가 뭐냐함은, 이 모델의 성능은 알겠는데... 어찌 해석해야할지 난감할때가 많다는 것이다.
Decision 트리를 제외하곤 세부과정들에서 만들어진 트리들을 하나하나 그려보거나 뜯어볼 수 없으니.. 이를 어떻게 확인할 것이냐. 라는 의문속에 많은 데싸인들이 고통받아왔다.
pdpbox는 이를 해결하기 위해 나온 라이브러리이다.
특성값에 따라 타겟값이 증가하는지, 감소하는지를 알 수 있다.
이는 특성들을 선형적으로 변화시키면서 타겟이 어떻게 되는지를 보는것이다.
pdp에서는 최대 두 특성이 동시에 모델에 끼치는 영향을 볼 수 있으며 이를 통해 의존도를 볼 수 있다.
아주 간단하다. 모델넣고, Validation Data넣고, 그 모델의 Feature들을 이름을 넣어주고나서 확인하고싶은 feature를 입력하면된다.
#!pip install pdpbox
from pdpbox import pdp
feature = 'duration'
pdp_dist = pdp.pdp_isolate(model=xgb, dataset = X_val , model_features=X_val.columns, feature = feature)
pdp.pdp_plot(pdp_dist, feature)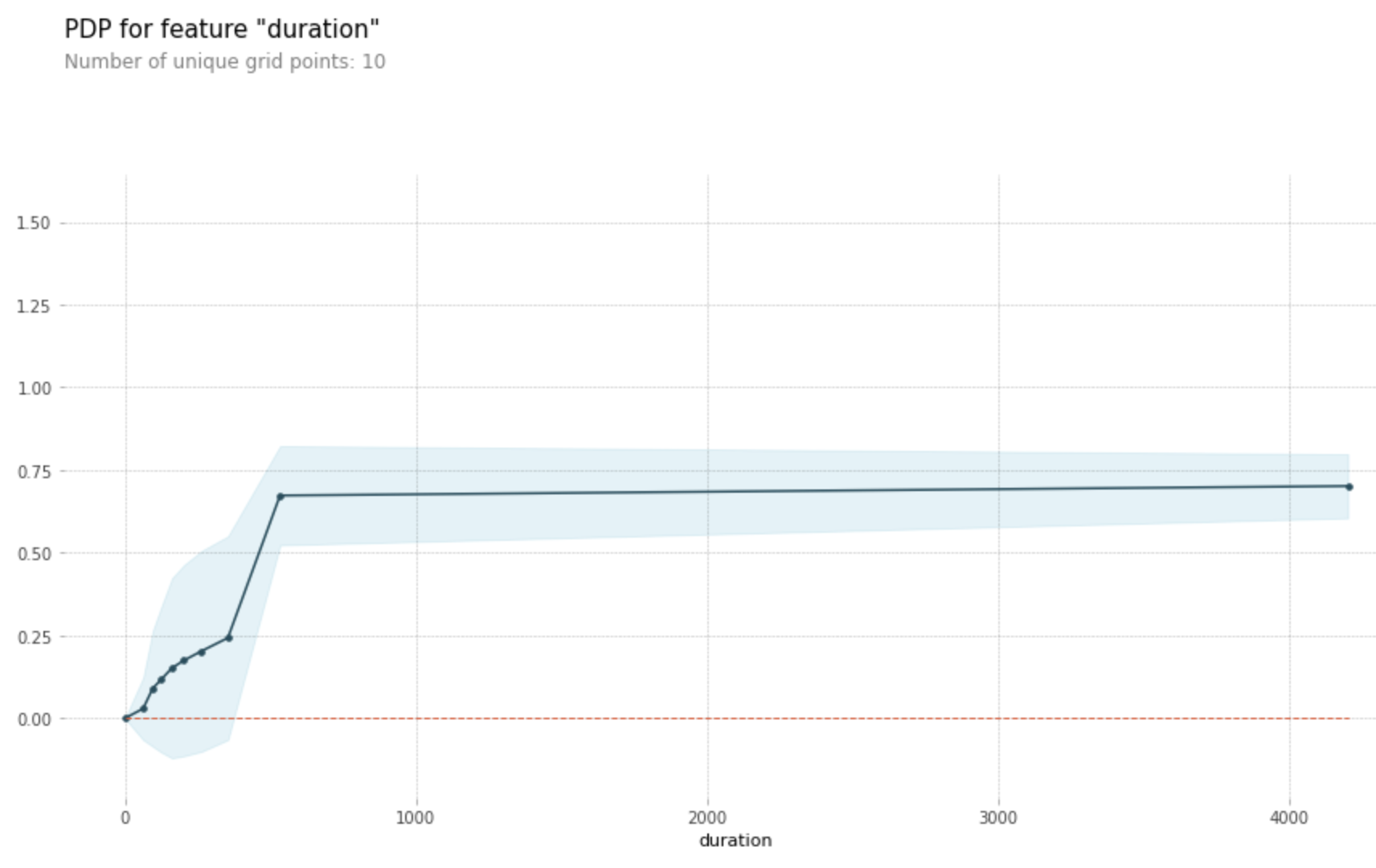
features = ['age', 'education']
interaction = pdp.pdp_interact(
model=xgb,
dataset=X_train,
model_features=X_train.columns,
features=features
)
pdp.pdp_interact_plot(interaction, plot_type='grid', feature_names=features, plot_params={'font_family':'NanumBarunGothic'});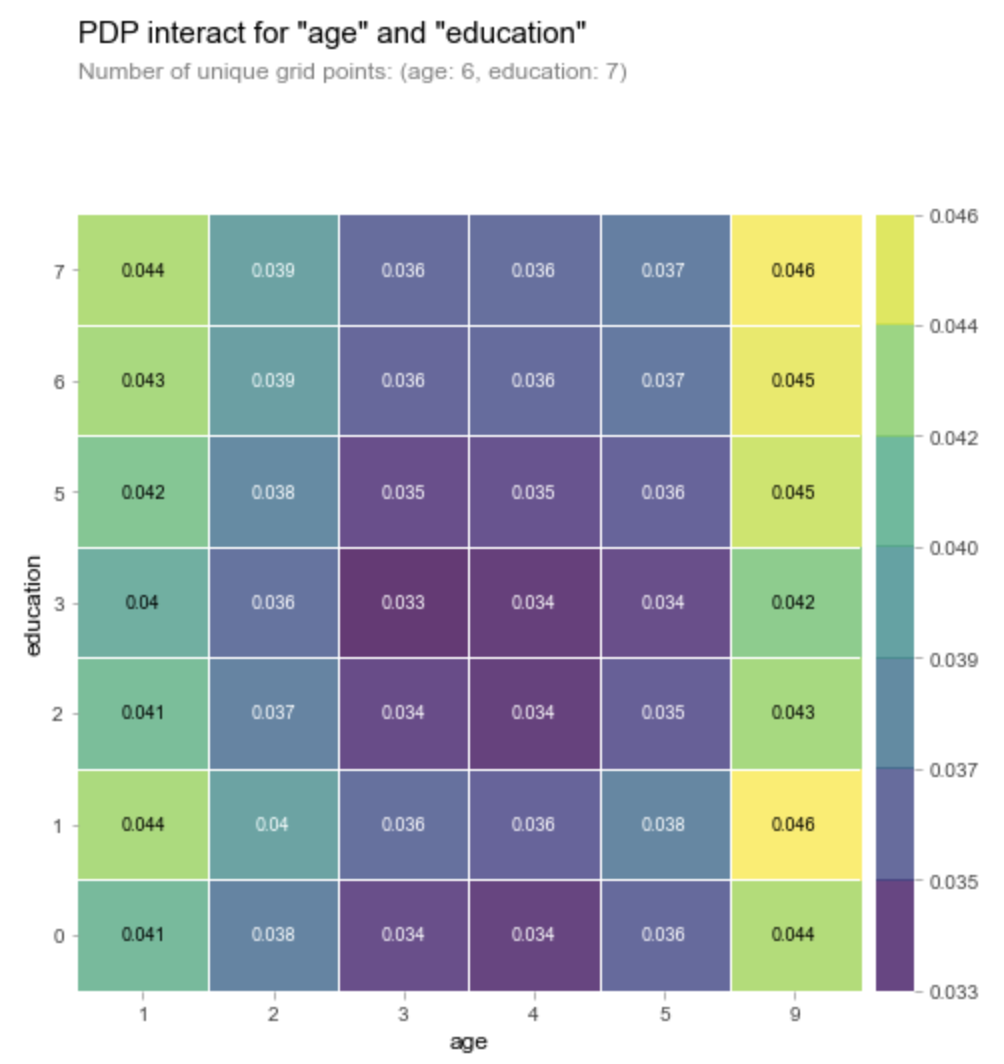
shap
블랙박스와도 같은 모델을 투명하게 바꿔준다.
게임이론에 나오는 shapely values에 기초하여 계산함.
[모든 특성들을 조합했을 때 결과]에서 [관심있는 특성들을 제외한 조합]으로 계산된 결과를 뺀 값이 그 특성이 기여한 가치라고 판단.
-> 그녀석이 없어지니 100점이 까였어 -> 그녀석의 기여도 ==100
데이터 특성 하나에 대한 설명 -> 개별 관측치 하나마다 특성의 영향도가 다르게 계산될 수 있음.
plot type 을 bar로 주면, feature_importance_ 와 비슷하게, 특성의 영향력을 전체적으로 평가해줌.
기존의 Permutation Importance (eli5)보다 정확하다. 그 이유는 특성중요도는 음의관계에 대하여 계산하지 않고, 서로 다른 특성들 간의 영향을 주는 경우 결과가 정확하지 않을 수 있기 때문이다.
# !pip install shap
import shap
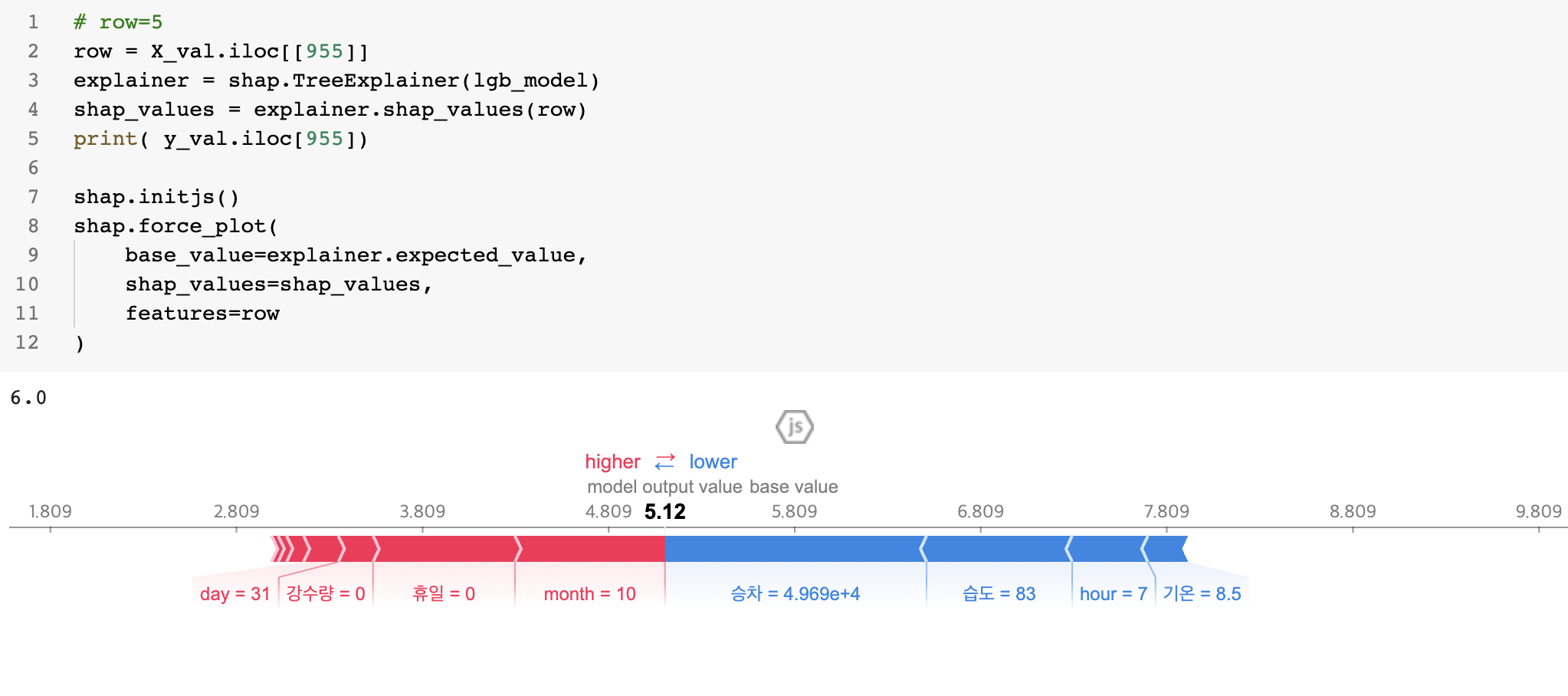
row=5
row = X_val.iloc[[9]]
explainer = shap.TreeExplainer(lgb_model)
shap_values = explainer.shap_values(row)
print(y_val.iloc[9])
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value,
shap_values=shap_values,
features=row
)
출처 :
pdpbox.readthedocs.io/en/latest/
PDPbox — PDPbox 0.2.0+13.g73c6966.dirty documentation
The common headache When using black box machine learning algorithms like random forest and boosting, it is hard to understand the relations between predictors and model outcome. For example, in terms of random forest, all we get is the feature importance.
pdpbox.readthedocs.io
SauceCat/PDPbox
python partial dependence plot toolbox. Contribute to SauceCat/PDPbox development by creating an account on GitHub.
github.com